Пошук в бінарних деревах
- теорія
- Мал. 3.2: Двійкове дерево
- Мал. 3.3: Незбалансоване бінарне дерево
- Мал. 3.4: Бінарне дерево після додавання вузла 18
У розділі 1 ми використовували двійковий пошук для пошуку даних в масиві. Цей метод надзвичайно ефективний, оскільки кожна ітерація вдвічі зменшує число елементів, серед яких нам потрібно продовжувати пошук. Однак, оскільки дані зберігаються в масиві, операції вставки і видалення елементів не настільки ефективні. Двійкові дерева дозволяють зберегти ефективність всіх трьох операцій - якщо робота йде з "випадковими" даними. В цьому випадку час пошуку оцінюється як O (lg n). Найгірший випадок - коли вставляються впорядковані дані. В цьому випадку оцінка час пошуку - O (n). Подробиці ви знайдете в роботі Кормена [2001] .
теорія
Двійкове дерево - це дерево, у якого кожен вузол має не більше двох спадкоємців. Приклад бінарного дерева наведено на рис. 3.2. Припускаючи, що k містить значення, збережене в даному вузлі, ми можемо сказати, що бінарне дерево має наступну властивість: у всіх вузлів, розташованих зліва від даного вузла, значення відповідного поля менше, ніж k, у всіх вузлів, розташованих праворуч від нього, - більше. Вершину дерева називають його коренем, вузли, у яких відсутні обидва спадкоємця, називаються листям. Корінь дерева на рис. 3.2 містить 20, а листя - 4, 16, 37 і 43. Висота дерева - це довжина наідліннейшего із шляхів від кореня до листя. У нашому прикладі висота дерева дорівнює 2.
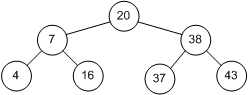
Мал. 3.2: Двійкове дерево
Щоб знайти в дереві якесь значення, ми стартуємо з кореня і рухаємося вниз. Наприклад, для пошуку числа 16, ми помічаємо, що 16 <20, і тому йдемо вліво. При другому порівнянні бачимо, що 16> 7, і тому ми рухаємося вправо. Третя спроба успішна - ми знаходимо елемент з ключем, рівним 16.
Кожне порівняння вдвічі зменшує кількість елементів, що залишилися. В цьому відношенні алгоритм схожий на двійковий пошук в масиві. Однак, все це вірно тільки в випадках, коли наше дерево збалансовано. На рис. 3.3 показано інше дерево, що містить ті ж елементи. Незважаючи на те, що це дерево теж бінарне, пошук в ньому схожий, скоріше, на пошук в однозв'язного списку, час пошуку збільшується пропорційно числу запам'ятовуються елементів.
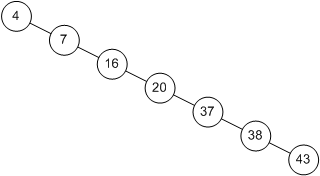
Мал. 3.3: Незбалансоване бінарне дерево
Вставка і видалення
Щоб краще зрозуміти, як дерево стає незбалансованим, подивимося на процес вставки пильніше. Щоб вставити 18 в дерево на рис. 3.2 ми спочатку повинні знайти це число. Пошук приводить нас в вузол 16, де благополучно завершується. Оскільки 18> 16, ми просто додає вузол 18 в якості правого нащадка вузла 16 (рис. 3.4).
На цьому прикладі добре видно, як виникає незбалансованість дерева. Якщо дані надходять в порядку зростання, кожен новий вузол додається праворуч від останнього вставленого. Це призводить до одного довгого списку. Зверніть увагу: чим більше "випадкові" надходять дані, тим більш збалансованим виходить дерево.
Видалення виробляються приблизно так само - необхідно тільки подбати про збереження структури дерева. Наприклад, якщо з дерева на рис. 3.4 видаляється вузол 20, його спочатку потрібно замінити на вузол 37. Це дасть дерево, зображене на рис. 3.5. Міркування тут приблизно такі. Нам потрібно знайти нащадка вузла 20, праворуч від якого розташовані вузли з великими значеннями. Таким чином, нам потрібно вибрати вузол з найменшим значенням, розташований праворуч від вузла 20. Щоб знайти його, нам і потрібно спочатку спуститися на крок вправо (потрапляємо в вузол 38), а потім на крок вліво (вузол 37); ці двокрокового спуски тривають, поки ми не прийдемо в кінцевий вузол, лист дерева.
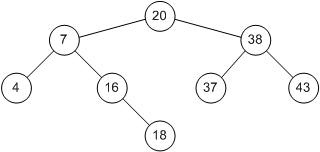
Мал. 3.4: Бінарне дерево після додавання вузла 18
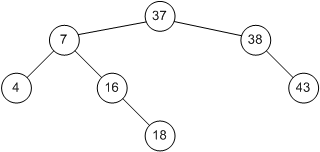
Мал. 3.5: Бінарне дерево після видалення вузла 20
Реалізація
В реалізації алгоритму на Сі оператори typedef T і compGT слід змінити так, щоб вони відповідали даним, збереженим в дереві. Кожен вузол Node містить покажчики left, right на лівого і правого нащадків, а також покажчик parent на предка. Власне дані зберігаються в поле data. Адреса вузла, що є коренем дерева зберігається в укзателе root, значення якого на самому початку, природно, NULL. Функція insertNode запитує пам'ять під новий вузол і вставляє вузол в дерево, тобто встановлює потрібні значення потрібних покажчиків. Функція deleteNode, навпаки, видаляє вузол з дерева (тобто встановлює потрібні значення потрібних покажчиків), а потім звільняє пам'ять, яку займав вузол. Функція findNode шукає в дереві вузол, що містить задане значення.