Оптимізація продуктивності за допомогою Concurrency Visualizer в Visual Studio 2010
- Подання CPU Utilization
- подання Threads
- категорії блокування
- Залежності між потоками
- Звіти
- подання Cores
- Підтримка PPL, TPL і PLINQ
- збір профілю
- Зв'язування візуалізацій з фазами роботи програми
- Ресурси і помилки
У наш час багатоядерні процесори широко поширені, і продуктивність однопоточних програм на нових процесорах швидше за все залишиться приблизно на тому ж рівні, що і на старих. А це фактор, що підсилює тиск на розробників ПЗ, щоб вони краще використовували паралелізм.
Паралельне програмування - штука складна з багатьох причин, але в цій статті я хотів би зосередитися на питаннях продуктивності паралельних програм. Багатопотокові програми не тільки схильні до тих же проблем, що й послідовні реалізації, наприклад низьку продуктивність через неефективні алгоритмів, неправильного використання кеша і занадто інтенсивного введення-виведення, а й страждають від помилок розпаралелювання. Продуктивність і масштабованість паралельних програм можуть бути обмежені неправильним розподілом навантаження, надмірними витратами на синхронізацію та ін.
Розуміння таких вузьких місць для продуктивності вимагало раніше ґрунтовного оснащення засобами моніторингу та протоколювання, а також аналізу розробниками-експертами. Але навіть для такої еліти розробників оптимізація продуктивності була утомливих і тривалим процесом.
Незабаром відбудуться зміни на краще. Visual Studio 2010 включає новий засіб профілювання - Concurrency Visualizer, який значно полегшить тягар аналізу продуктивності паралельних програм. Більш того, Concurrency Visualizer допоможе розробникам аналізувати послідовні додатки на предмет можливості їх розпаралелювання. У цій статті я дам огляд функцій Concurrency Visualizer в Visual Studio 2010, а також деякі корисні поради щодо його використання.
Подання CPU Utilization
Concurrency Visualizer включає кілька інструментів для візуалізації і створення звітів. Підтримується три основних подання (режиму перегляду): CPU Utilization (ступінь використання процесора), Threads (потоки) і Cores (ядра).
Подання CPU Utilization (рис. 1) задумано як відправна точка в Concurrency Visualizer. По осі x показується час, що минув з початку трасування і до кінця роботи програми (або до закінчення трасування - в залежності від того, що закінчиться раніше). По осі y показується число логічних ядер процесора в системі
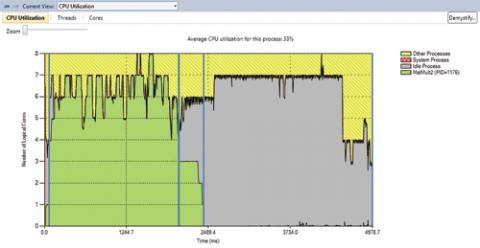
Мал. Подання CPU Utilization
Перш ніж описувати призначення кожного уявлення, важливо, щоб ви зрозуміли, що таке логічне ядро. Один процесор в наш час може містити кілька мікропроцесорів, які називають фізичними ядрами. Кожна фізична ядро може виконувати кілька потоків відразу. У такому випадку говорять про одночасну многопоточности (simultaneous multithreading, SMT); Intel називає це технологією Hyper-Threading. Кожен апаратно підтримуваний потік в одному фізичному ядрі з підтримкою SMT представляється операційній системі як логічне ядро.
Якщо ви здійснюєте трасування в чотирьохядерний системі без підтримки SMT, по осі y будуть показані чотири логічних ядра. Але якщо кожне ядро в вашій чотирьохядерний системі здатне виконувати два SMT-потоку, тоді по осі y будуть показуватися вісім логічних ядер. Суть в тому, що число логічних ядер відображає кількість потоків, які можуть одночасно працювати в вашій системі, а не число фізичних ядер.
Тепер повернемося до подання. На графіку відображаються чотири області, позначені в легенді. Зелена область відображає середню кількість логічних ядер, яке аналізоване додаток використовує в будь-який момент під час циклу профілювання. Решта логічні ядра або простоюють (зафарбовуються сірим кольором), або задіяні процесом System (червоний колір), або використовуються іншими процесами в системі (жовтий).
Вертикальні сині смужки в цьому поданні відповідають додатковому механізму, який дозволяє оснащувати програмістам свій код так, щоб візуалізації корелювали з конструкціями додатками. Я поясню, як це робиться, пізніше.
Повзунок Zoom угорі ліворуч дає можливість збільшувати яку-небудь ділянку уявлення для отримання деталей, а елемент управління «графік» (graph control) підтримує горизонтальну смугу прокрутки в разі збільшеного зображення. Те ж саме можна робити, клацнувши лівою кнопкою миші і переміщуючи курсор на самому графіку.
Це уявлення служить трьом основним цілям. По-перше, якщо вас цікавить розпаралелювання додатки, шукайте області виконання, які виявляють значні обсяги послідовної роботи з процесором (вони показуються як довгі зелені області на рівні одного ядра по осі y), або області, де процесор використовується досить слабо (області зеленого кольору немає або висота цієї області суттєво менше одиниці в середньому). Обидві ці обставини зазвичай вказують на можливість розпаралелювання. Робота, що вимагає інтенсивного використання процесора, може бути прискорена розпаралелюванням, а області, де спостерігається несподівано мале використання процесора, як правило, пов'язані з блокуванням (можливо, через введення-виведення), і тут паралельна обробка допоможе за рахунок перекриття виконувати іншу корисну роботу.
По-друге, якщо ви намагаєтеся оптимізувати своє паралельне додаток, це уявлення дозволяє побачити реальну ступінь його паралелізму при виконанні. Просте вивчення цього графіка зазвичай робить явними багато поширені помилки, пов'язані з паралельною роботою. Наприклад, ви можете спостерігати неправильний розподіл навантаження у вигляді східчастих областей на графіку або конкуренцію за синхронизирующие об'єкти, яка проявляється як послідовне виконання замість паралельного.
По-третє, оскільки ваш додаток «живе» в системі, яка швидше за все виконує масу інших програм, що конкурують за її ресурси, важливо знати, чи впливають інші додатки на продуктивність вашого. Якщо вплив інших програм не очікувалося, непогано для початку відключити сторонні додатки і сервіси, щоб підвищити точність даних; оптимізація продуктивності вимагає ітеративного підходу. Іноді вплив виявляється іншими процесами, з якими взаємодіє ваше додаток. У будь-якому випадку за допомогою цього подання ви побачите, чи є такий вплив, а потім, використовуючи уявлення Threads, визначте, які саме процеси впливають на ваше додаток (про це поданні я розповім пізніше).
Ще один варіант, здатний допомогти в зменшенні впливу інших програм, - застосування засобів профілювання командного рядка для збору трасувань даних поза інтегрованого середовища розробки (IDE) Visual Studio.
Звертайте увагу на деякі вікна виконання, які викликають ваш інтерес, збільшуйте їх, а потім перемикайтеся в уявлення Threads для подальшого аналізу. Ви завжди можете повернутися в вихідне уявлення, щоб вибрати іншу область і повторити весь процес.
подання Threads
Подання Threads (рис. 2) містить безліч засобів детального аналізу і звітів в Concurrency Visualizer. Саме тут ви знаходите інформацію, прояснює поведінку, які ви виявляєте в уявленнях CPU Utilization або Cores. Крім того, тут є дані, що дозволяють по можливості пов'язувати поведінку додатки з його вихідним кодом. У цьому поданні є три основних компоненти: тимчасова шкала (timeline), активна легенда (active legend) і елемент управління «вкладка» для отримання звіту / детальних відомостей.
Як і в CPU Utilization, в поданні Threads по осі x показується час. (При перемиканні між уявленнями в Concurrency Visualizer діапазон часу, що показується по осі x, зберігається.) Однак в поданні Threads по осі y розміщуються два типи горизонтальних каналів.
Верхні канали зазвичай відводяться під фізичні диски у вашій системі, якщо вони активні в профілі вашого застосування. На кожен диск створюється два канали: один для операцій читання, а інший для операцій запису. Ці канали показують звернення до диска з потоків вашого застосування або процесу System. (Звернення з System показуються тому, що вони іноді відображають роботу, виконувану від імені вашого процесу, наприклад підкачування сторінок пам'яті.) Кожна операція читання або запису малюється як прямокутник. Довжина прямокутника позначає затримку доступу, пов'язану в тому числі з приміщенням в чергу; через це прямокутники можуть перекриватися.
Щоб визначити, до яких файлів був доступ в певний момент, виберіть прямокутник, клацнувши його лівою кнопкою миші. Після цього вікно звітів нижче переключиться на вкладку Current Stack. У ній перераховуються імена файлів, які зчитувалися або записувалися (в залежності від обраного каналу диска). До аналізу введення-виведення я ще повернуся.
Слід розуміти, що не всі файлові операції читання і запису, що виконуються додатком, можуть бути видні саме тоді, коли вони очікуються. Справа в тому, що файлова система використовує буферизацию, що дозволяє виконувати деякі операції дискового введення-виведення без звернення до фізичного диску.
Решта каналів на тимчасовому графіку перераховують всі потоки, що існували в додатку за період профілювання. Для кожного потоку, якщо інструмент виявляє будь-яку активність в ході профілювання, показується його стан аж до завершення.
Якщо потік виконується в даний момент, що відзначається зеленим сегментом Execution, то Concurrency Visualizer відображає, що цей потік робив. Отримати ці дані можна двома способами. Перший - клацнути зелений сегмент, і тоді ви побачите найближчий стек викликів (в межах +/- 1 мс) у вкладці Current Stack.
Ви також можете створити звіт з вибірками в профілі для видимого діапазону часу, щоб з'ясувати, де виконується найбільша частина роботи. Якщо клацнути мітку Execution в активній легендою, в звіті з'явиться вкладка Profile Report. На ній є два засоби, які допомагають зменшити складність. Одне з них - придушення шуму, яке за замовчуванням видаляє стеки викликів, відповідальні за 2% і менше вибірок в профілі. Цей поріг можна міняти. Інший засіб під назвою Just My Code дозволяє скоротити кількість фреймів стека, видаляючи з звіту ті, які відносяться до системних DLL. Щодо звітів поговоримо докладніше пізніше.
Перш ніж продовжити, хотів би звернути вашу увагу ще на кілька функцій, за допомогою яких можна регулювати деталізацію звітів і уявлень. Ви будете часто стикатися з ситуаціями, де показується багато потоків, але деякі з них нічого корисного при даному прогоні кошти профілювання не роблять. Крім фільтрації звітів на основі тимчасового діапазону, Concurrency Visualizer також дозволяє виконувати фільтрацію по активним потокам. Якщо вас цікавлять потоки, що роблять якусь роботу, ви можете вибрати в Sort By сортування потоків за часом, протягом якого вони знаходяться в стані Execution. Потім ви можете вибрати групу потоків, що не роблять нічого особливо корисного, і приховати їх, або клацнувши правою кнопкою миші і вибравши з контекстного меню команду Hide, або натиснувши кнопку Hide на панелі інструментів у верхній частині подання. Сортувати можна за всіма категоріями станів потоків, а потім приховувати / відображати те, що вам потрібно.
Ефект від приховування потоків полягає в тому, що вони віддаляються з усіх звітів в добавок до приховування їх каналів з тимчасової шкали. Актуальність всієї статистики і звітів кошти підтримується динамічно в ході фільтрації по потокам і тимчасового диапозону.
категорії блокування
Потоки можуть блокуватися з багатьох причин. Подання Threads намагається ідентифікувати причину, по якій блокований потік, зіставляючи кожен екземпляр з набором категорій блокування. Я сказав «намагається», тому що ця категоризація іноді виявляється неточною (чому - трохи пізніше), а значить, ставитися до неї слід як до зразкової оцінки. Як вже говорилося, уявлення Threads відображає всі затримки потоків і точно показує періоди їх виконання. Ви повинні приділяти основну увагу категоріям, відповідальним за значні затримки, виходячи з розуміння поведінки свого застосування.
Крім того, уявлення Threads відображає стек викликів, при якому виконання потоку зупинилося, на вкладці Current Stack - для цього клацніть подію блокування. Клацнувши фрейм стека в вікні Current Stack, ви перейдете в файл вихідного коду (якщо є), на рядок з тим номером, де викликана наступна функція. Це важлива функція продуктивності кошти.
Давайте розглянемо різні категорії блокування.
Synchronization (синхронізація) Майже всі блокуючі операції можна зіставити з нижчого рівня синхронізуючими механізмами в Windows. Concurrency Visualizer намагається зіставити події блокування з цією категорією по таким синхронизирующим API, як EnterCriticalSection і WaitForSingleObject, але іноді до цієї категорії можуть бути віднесені інші операції, які викликають внутрішню синхронізацію. Отже, найчастіше це дуже важлива категорія блокування при аналізі на предмет оптимізації продуктивності - не тільки через значущості витрат синхронізації, але і через те, що вона може відображати інші важливі причини затримок у виконанні.
Preemption (витіснення) У цю категорію входить витіснення через закінчення кванта часу, коли закінчується частка часу, виділеного потоку на виконуючому його ядрі. Сюди ж включається витіснення відповідно до правил планування в операційній системі, наприклад через появу готового до виконання потоку іншого процесу з більш високим пріоритетом. Concurrency Visualizer також включає сюди інші причини витіснення, зокрема переривання і LPC, які можуть перервати виконання потоку. При кожній такій події ви можете отримати ім'я / ідентифікатор процесу і ідентифікатор його потоку, який витіснив ваш потік, просто затримавши курсор миші над областю витіснення і дочекавшись появи підказки (або клацнувши жовту область і переглянувши вміст вкладки Current Stack). Це може дуже стати в нагоді для розуміння кореневих причин появи жовтих ділянок в поданні CPU Utilization.
Sleep (засипання) Ця категорія використовується для звітів про події блокування потоків в результаті явного запиту потоку на засинання або добровільного звільнення свого ядра.
Paging / Memory Management (управління пам'яттю / підкачкою) Ця категорія охоплює події блокування, пов'язані з управлінням пам'яттю, в тому числі будь-які блокують операції, запущені системним диспетчером пам'яті у відповідь на будь-яку дію програми. Тут відображаються помилки сторінок, конкуренція за виділення певних областей пам'яті або блокування на певних ресурсах. Особливо важливі помилки сторінок, так як вони тягнуть за собою операції введення-виведення. Бачачи подія блокування через помилки сторінки, ви повинні вивчити стек викликів і знайти відповідне подія введення-виведення в дисковому каналі, якщо ця помилка сторінки зажадала введення-виведення. Ви можете з'ясувати причину помилки сторінки (через завантаження DLL або підкачки), клацнувши відповідний сегмент введення-виведення і дізнавшись ім'я причетного до помилки файлу.
I / O (введення-виведення) У цю категорію включаються такі події, як блокування на операціях читання і запису файлів, деяких мережевих операціях на сокеті і зверненнях до реєстру. Ряд операцій, які деякими вважаються мережевими, можуть з'являтися не тут, а в категорії синхронізації. Справа в тому, що багато операцій введення-виведення використовують синхронизирующие механізми для блокування. Як і в випадку категорії управління пам'яттю / підкачкою, коли ви бачите подія блокування через введення-виведення, ви повинні перевірити, чи є відповідне звернення до диска в дискових каналах. Щоб це було робити простіше, використовуйте кнопки-стрілки на панелі інструментів для зміщення своїх потоків ближче до дискового каналу. Для цього виберіть канал потоку, клацнувши його мітку зліва, а потім клацніть відповідну кнопку на панелі інструментів.
UI Processing (обробка UI) Це єдина форма блокування, яка зазвичай бажана. Вона відображає стан потоку, який знаходиться в циклі прийому (прокачування) повідомлень. Якщо ваш UI-потік проводить більшу частину часу саме в цьому стані, значить, ваше додаток швидко відповідає на дії користувача. З іншого боку, якщо UI-потік виконує зайву роботу або блокується з інших причин, то з точки зору користувача UI буде здаватися завислим. Ця категорія відкриває широкі можливості у вивченні «чуйності» вашої програми і його оптимізації.
Залежності між потоками
Одна з найцінніших функцій уявлення Threads - можливість визначати залежно синхронізації між потоками. На рис. 2 я вибрав сегмент затримки через синхронізації. Цей сегмент збільшений, і він виділений іншим кольором (червоним). На вкладці Current Stack показується стек викликів потоку в цей момент. Вивчаючи стек викликів, ви можете знайти API, виклик якого привів до блокування потоку.
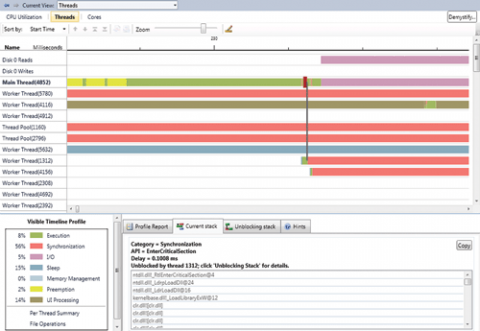
Мал. подання Threads
Інший засіб візуалізації - лінія, що з'єднує сегмент блокування з сегментом виконання в іншому потоці. Якщо така лінія видна, вона вказує потік, який припинив блокування вашого потоку. Крім того, в цьому випадку можна відкрити вкладку Unblocking Stack, щоб дізнатися, що робив неблокірованние потік, коли звільнив ваш потік.
Наприклад, якщо блокований потік чекав на критичній секції Win32, ви побачили б сигнатуру EnterCriticalSection в стеці викликів блокованого потоку. А коли він розблокується, ви помітили б сигнатуру LeaveCriticalSection в стеці викликів неблокірованние потоку. Це засіб дуже корисно при аналізі поведінки складного додатка.
Звіти
Звіти профілів дозволяють легко знаходити найбільш значущі фактори, що впливають на продуктивність програми. У поданні Threads пропонуються чотири типи звітів:
профілі вибірки виконання (execution sampling profiles), профілі блокування (blocking profiles), звіти по файлових операціях і зведення по кожному потоку. Всі звіти доступні через легенду. Наприклад, щоб отримати звіт профілю виконання, клацніть в легенді мітку Execution. На вкладці Profile Report буде створено відповідний звіт. Цей звіт виглядає приблизно так, як показано на рис. 3.
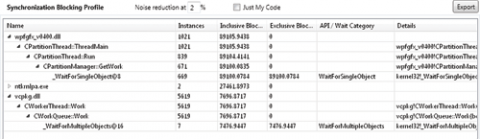
Мал. 3 Типовий звіт профілювання
У звіті профілю виконання Concurrency Visualizer аналізує всі стеки викликів, отримані при вибірках даних в процесі виконання вашої програми (зелені сегменти), і порівнює їх із загальних фреймам стека, щоб допомогти вам зрозуміти структуру процесу виконання програми. Даний інструмент також обчислює всі витрати (які включають і виключають) для кожного фрейму. Inclusive samples вказує на все прикладів на даному шляху виконання, включаючи всі шляхи, що знаходяться під ним. Exclusive samples відповідає числу прикладів, залишених графом викликів фрейму стека.
Щоб отримати профіль блокування, клацніть потрібну категорію блокування в легенді. Цей звіт генерується за аналогією зі звітом профілю виконання, але включають і виключають стовпці тепер відповідають часу блокування, зіставлення зі стеками викликів або фреймами в звіті. Ще один стовпець показує число примірників блокувань, зіставлених з даними фреймом стека в дереві викликів.
Ці звіти - зручний засіб, що дозволяє розставити пріоритети в оптимізації продуктивності і виявити частини програми, відповідальні за найбільш значущі затримки. Звіт по витісненню носить чисто інформаційний характер і зазвичай не надає ніяких даних для подальших дій з саму природу цієї категорії. Всі звіти дозволяють перемикатися в відповідні місця вихідного коду. Це можна зробити, клацнувши правою кнопкою миші потрібний фрейм стека. Що з'являється після цього контекстного меню дозволяє перейти або до визначення функції (команда View Source) або до ділянки в додатку, де ця функція була викликана (команда View Call Sites). Якщо виклики виходили від декількох блоків коду, вам буде запропоновано декілька команд. Це забезпечує безшовну інтеграцію діагностичних даних в процес розробки, що допомагає налаштовувати поведінку програми. Звіти також можна експортувати для порівнянь між профілями.
Звіт File Operations (рис. 4) включає зведення по всіх операціях файлового читання і запису, видимим в поточному часовому діапазоні. Для кожного файлу Concurrency Visualizer перераховує потік додатку, який звертається до нього, число операцій читання і запису, загальна кількість лічених або записаних байтів, а також загальну затримку читання або запису. Крім відображення файлових операцій, прямо пов'язаних з додатком, Concurrency Visualizer показує і ті, які виконуються процесом System. Це зроблено через те, що вони можуть виконуватися від імені вашого застосування. Експорт звіту дозволяє проводити порівняння між профілями.
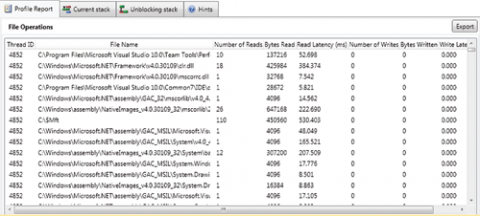
Мал. Звіт File Operations
Звіт Per Thread Summary (рис. 5) представляє собою стовпчастий графік для кожного потоку. Стовпчик ділиться між різними станами потоку. Це може стати в нагоді для відстеження вашого прогресу в оптимізації. Експортуючи ці дані на кожній ітерації оптимізації, ви зможете документувати процес оптимізації. На графіку показуються не всі потоки додатки, якщо воно створює занадто велика їх кількість, що не уміщається в вікно подання.
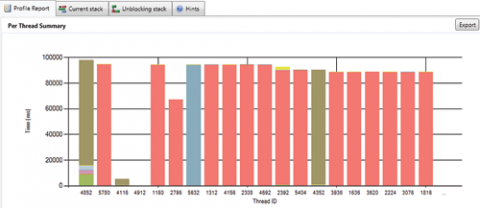
Мал.
подання Cores
Надмірне перемикання контекстів може негативно позначитися на продуктивності додатка, особливо коли потоки мігрують між ядрами або процесорами при відновленні свого виконання. Справа в тому, що запускається потік завантажує необхідні команди і дані (часто звані робочим набором) в ієрархію кешей. Відновлюючи виконання, особливо на іншому ядрі, потік може постраждати від значної затримки через перезавантаження свого робочого набору з пам'яті або інших кешей в системі.
Зменшити ці витрати можна двома найбільш поширеними способами. Розробник може або скоротити частоту перемикань контекстів, усунувши нижележащие причини цього, або використовувати прив'язку (affinity) до певного процесору або ядру. Перший варіант завжди краще, так як прив'язка потоків до певних процесорам або ядер може стати джерелом інших проблем з продуктивністю і її можна застосовувати тільки в особливих обставинах. Подання Cores - це інструмент, що допомагає виявляти занадто часте перемикання контекстів або помилки, пов'язані з прив'язкою потоків.
Як і в інших виставах, в поданні Cores показується тимчасова шкала, де час відкладається по осі x. Кількість логічних ядер в системі показується по осі y. Кожен потік додатку открашівается своїм кольором, а сегменти виконання потоків малюються на каналах ядер. Легенда і статистика перемикань контекстів відображаються в нижній секції (рис. 6).
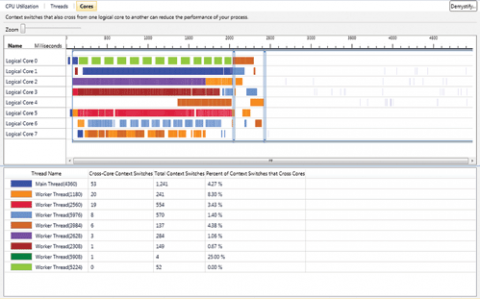
Мал. подання Cores
Статистика допомагає визначати потоки із занадто частим перемиканням контексту і міграцією між ядрами. Потім це уявлення можна використовувати для пошуку областей виконання, де аналізовані потоки перериваються або часто переключаються між ядрами (колірні виділення допомагають в пошуку). Знайшовши потрібну область, ви збільшуєте її і перемикаєтеся в уявлення Threads, щоб зрозуміти, що викликає перемикання контексту, і по можливості усунути причини (наприклад, зменшивши конкуренцію за критичну секцію). Помилки прив'язки потоків також проявляють себе в деяких випадках, коли два або більше потоків конкурують за одне ядро, в той час як інші ядра фактично простоюють.
Підтримка PPL, TPL і PLINQ
Concurrency Visualizer підтримує моделі паралельного програмування, що надаються Visual Studio 2010, а також існуючі моделі програмування з використанням керованого і некерованого коду. Деякі з нових паралельних конструкцій - parallel_for в Parallel Pattern Library (PPL), Parallel.For в Task Parallel Library (TPL) і PLINQ-запити - включають візуальні підказки в цьому засобі профілювання, які дозволяють звернути увагу на відповідні області виконання.
Для підтримки такої функціональності PPL вимагає включення трасування, як показано в прикладі:
Concurrency :: EnableTracing (); parallel_for (0, SIZE, 1, [&] (int i2) {for (int j2 = 0; j2 <SIZE; j2 ++) {A [i2 + j2 * SIZE] = 1.0; B [i2 + j2 * SIZE] = 1.0; C [i2 + j2 * SIZE] = 0,0;}}); Concurrency :: DisableTracing ();
При включеній трасування в уявленнях Threads і Cores початок і кінець області виконання parallel_for відзначаються вертикальними маркерами. Вертикальні смужки з'єднуються з горизонтальними смужками вгорі і внизу уявлення. Затримавши курсор миші над горизонтальною смужкою, ви отримаєте підказку з ім'ям конструкції (рис. 7).
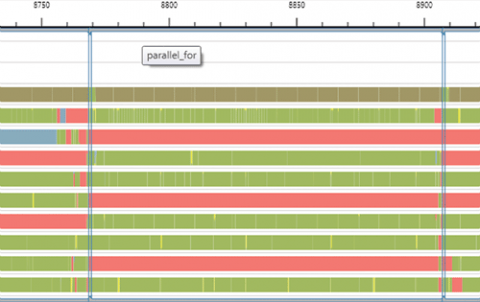
Мал. Приклад візуального маркера parallel_for в поданні Threads
TPL і PLINQ не вимагають ручного включення трасування для підтримки еквівалентної підтримки в Concurrency Visualizer.
збір профілю
Concurrency Visualizer підтримує методи як запуску програми, так і підключення до нього для збору профілю. Це поведінка точно відповідає звичному Visual Studio Profiler. Новий сеанс профілювання можна ініціювати через меню Analyze, або запустивши Performance Wizard (рис. 8), або вибравши команду Profiler | New Performance Session. В обох випадках Concurrency Visualizer активується вибором методу профілювання Concurrency і подальшого вказівки параметра Visualize the behavior of a multithreaded application (візуалізувати поведінка многопоточного додатки).
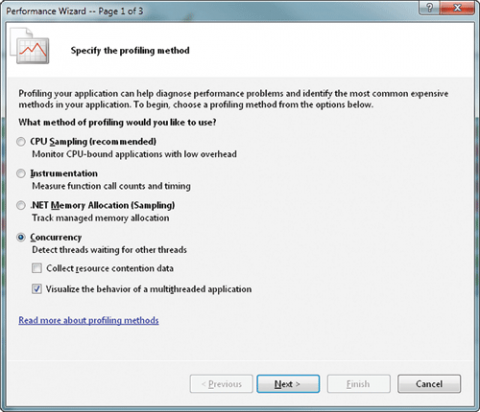
Мал. Діалог для вибору методу профілювання в Performance Wizard
Утиліти командного рядка в Visual Studio Profiler дозволяють збирати трасування Concurrency Visualizer, а потім аналізувати її в IDE. Це дає можливість тим, хто зацікавлений в серверних сценаріїв, де установка IDE неприпустима, збирати трасування з мінімальним втручанням.
Ви помітите, що в Concurrency Visualizer не інтегрована підтримка профілювання ASP.NET-додатків. Проте його можна підключати до хост-процесу (зазвичай w3wp.exe), в якому виконується ваше ASP.NET-додаток.
Так як Concurrency Visualizer використовує Event Tracing for Windows (ETW), він вимагає адміністративних привілеїв для збору даних. Так що запускайте IDE як адміністратор, інакше з'явиться пропозиція зробити це. В останньому випадку IDE буде перезапущено з правами адміністратора.
Зв'язування візуалізацій з фазами роботи програми
Ще один засіб в Concurrency Visualizer - додаткова бібліотека оснащення (instrumentation library), що дозволяє розробникам налаштовувати уявлення, відзначаючи маркерами цікаві для них фази роботи програми. Це вкрай важливо для спрощення кореляції між візуалізаціями і поведінкою програми. Бібліотека оснащення називається Scenario, і її можна завантажити з сайту MSDN Code Gallery за посиланням code.msdn.microsoft.com/scenario. Ось приклад, де використовується додаток на C:
#include "Scenario.h" int _tmain (int argc, _TCHAR * argv []) {myScenario = new Scenario (0, L "Scenario Example", (LONG) 0); myScenario-> Begin (0, TEXT ( "Initialization")); // Initialization code goes here myScenario-> End (0, TEXT ( "Initialization")); myScenario-> Begin (0, TEXT ( "Work Phase")); // Main work phase goes here myScenario-> End (0, TEXT ( "Work Phase")); exit (0); }
Використовувати цю бібліотеку нескладно; ви включаєте заголовки Scenario і пов'язуєте свою програму з бібліотекою. Потім ви створюєте один або більше об'єктів Scenario і помечаете початок і кінець кожної фази викликами методів Begin і End відповідно. Крім того, ви можете вказати цим методам ім'я кожної фази. Візуалізація ідентична показаної на рис. 7 з тим винятком, що підказка буде показувати ім'я фази, заданий вами в коді. Маркери сценарію також видно в поданні CPU Utilization, в якому інші маркери не відображаються. Бібліотека поставляється з еквівалентної керованої реалізацією.
Тут хотів би застерегти вас. Не слід занадто інтенсивно використовувати Scenario-маркери, так як інакше візуалізації будуть повністю приховані ними. Щоб уникнути цієї проблеми, інструмент значно скоротить кількість відображуваних маркерів, якщо виявить їх надмірне використання. Щоб уникнути цієї проблеми, інструмент значно скоротить кількість відображуваних маркерів, якщо виявить їх надмірне використання. Більш того, при вкладенні Scenario-маркерів буде відображатися тільки самий внутрішній маркер.
Ресурси і помилки
У Concurrency Visualizer багато коштів, які допомагають зрозуміти відображаються ним подання та звіти. Найцікавіше з таких засіб - кнопка Demystify в правому верхньому куті всіх уявлень. Клацнувши Demystify, ви побачите, що курсор миші придбав особливу форму, і тепер можете клацати їм будь-який елемент в поданні, за яким ви хотіли б отримати підказку. Це наш варіант контекстно-залежною довідки.
Крім того, є вкладка Tips, що містить більш детальну довідкову інформацію, в тому числі посилання на галерею сигнатур візуалізації для найбільш поширених проблем продуктивності.
Як уже згадувалося, інструмент використовує ETW. Деякі події, необхідні Concurrency Analyzer, відсутні в Windows XP або Windows Server 2003, тому інструмент підтримує тільки Windows Vista, Windows Server 2008, Windows 7 і Windows Server 2008 R2, в тому числі їх 32- і 64-розрядні версії.
Інструмент також підтримує як некеровані програми на C / C ++, так і .NET-додатки (виключаючи .NET 1.1 і більш ранні версії). Якщо ви використовуєте Неподдерживается платформу, то вивчіть інший корисний інструмент для аналізу паралельних програм в Visual Studio 2010, який включається при виборі параметра Collect resource contention data (збирати дані про конкуренцію за ресурси).
У певних випадках, коли в сценарії профілювання спостерігається висока активність або коли виникає конкуренція за ресурси введення-виведення з боку інших додатків, важливі трасувальні події можуть бути втрачені. А це призводить до помилок при аналізі трасування. Є два способи вирішити цю проблему. По-перше, ви могли б спробувати повторити профілювання, але з меншим числом активних додатків, - це хороша методологія, що дозволяє мінімізувати стороннє вплив в процесі оптимізації додатки. В цьому випадку можна використовувати і утиліти командного рядка.
По-друге, ви можете збільшити кількість або розмір буферів пам'яті для ETW. Ми надаємо документацію по посиланню у вікні виводу, з якої можна дізнатися, як це робиться. Якщо ви виберете другий варіант, будь ласка, задайте загальний обсяг буферів мінімально необхідним для збору коректної трасування, так як ці буфери використовують важливі ресурси ядра.
Будь-діагностичний інструмент хороший тільки тоді, коли надає користувачеві потрібні дані. Concurrency Visualizer допоможе точно визначити кореневі причини проблем з продуктивністю з посиланнями на вихідний код, але для цього йому потрібен доступ до файлів символів. Ви можете додати сервери символів і шляхи до них в IDE, використовуючи діалог Tools | Options | Debugging | Symbols. Символи для вашого поточного рішення будуть включені неявно, але ви повинні самі вказати загальнодоступний сервер символів Microsoft, а також будь-які інші шляхи пошуку важливих файлів символів, специфічних для аналізованого додатки. Також гарною ідеєю буде включення кеша символів, так як це суттєво зменшить час аналізу профілю.
Хоча ETW надає механізм трасування з малими витратами, обсяг трасувань даних, зібраних Concurrency Visualizer, може бути дуже великим. Аналіз великих обсягів трасувань даних може виявитися дуже тривалим і привести до затримок в візуалізації. Як правило, профілі слід збирати протягом однієї-двох хвилин, щоб звести до мінімуму ймовірність появи згаданих проблем. У більшості випадків однієї-двох хвилин цілком достатньо для ідентифікації проблеми в додатку. Можливість підключення інструменту до виконуваного процесу теж допомагає уникати збору даних до досягнення вашим додатком певної фази в своїй роботі.
Джерел інформації по Concurrency Visualizer багато. Відповіді спільноти і групи розробників можна знайти на форумі з Visual Studio Profiler ( social.msdn.microsoft.com/forums/en-us/vstsprofiler/threads ). Додаткова інформація розташована в блозі групи розробників за адресою blogs.msdn.com/visualizeparallel , А також в моєму особистому блозі за адресою blogs.msdn.com/hshafi . Якщо у вас є які-небудь питання, що стосуються цього інструменту, будь ласка, не соромтеся і зв'язуйтеся зі мною або моєю групою. Ми раді поспілкуватися з людьми, які використовують наш Concurrency Visualizer, і ваші відгуки допомагають нам покращувати його.