Plik Robots.txt
- Czego możesz się spodziewać po tym artykule W tym artykule wyjaśniono, czym jest plik robots.txt...
- Synonimy dla
- Dlaczego plik robots.txt jest tak ważny?
- Czy twój robots.txt działa przeciwko tobie?
- Czy to wygląda na plik?
- Agent użytkownika w robots.txt
- Zabroń w robots.txt
- Zezwól w pliku robots.txt
- Korzystanie ze znaku wieloznacznego *
- Podaj koniec adresu URL za pomocą $
- Mapa witryny w robots.txt
- Uwagi
- Opóźnienie indeksowania w robots.txt
- Bing, Yahoo i Yandex
- Baidu
- Kiedy potrzebuję pliku robots.txt?
- Najlepsze praktyki dotyczące pliku robots.txt
- Kolejność wytycznych
- Tylko jedna grupa z wytycznymi na robota
- Bądź jak najbardziej konkretny
- Jednocześnie zdefiniuj wytyczne, które są przeznaczone dla wszystkich robotów i wskazówek przeznaczonych dla konkretnego robota
- Plik Robots.txt dla każdej (pod) domeny.
- Sprzeczne wytyczne: robots.txt vs. Google Search Console
- Sprawdź robots.txt po uruchomieniu
- Nie używaj notindeksu w pliku robots.txt
- Przykłady plików robots.txt
- Wszystkie roboty mają dostęp do całej strony internetowej
- Brak dostępu dla wszystkich robotów
- Brak dostępu do wszystkich botów Google
- Brak dostępu do wszystkich botów Google z wyjątkiem wiadomości Googlebot
- Brak dostępu do Googlebota i Slurpa
- Brak dostępu do dwóch katalogów dla wszystkich robotów
- Brak dostępu do jednego konkretnego pliku dla wszystkich robotów
- Brak dostępu do / admin / dla Googlebota i / private / dla Slurp
- Robots.txt dla WordPress
- Jakie są ograniczenia robots.txt?
- Strony są nadal wyświetlane w wynikach wyszukiwania
- Buforowanie
- Rozmiar pliku
- Często zadawane pytania dotyczące Openta
- 1. Czy mogę użyć pliku robots.txt, aby zapobiec wyświetlaniu stron na stronach wyników wyszukiwania?
- 2. Czy muszę uważać na plik robots.txt?
- 3. Czy nie wolno ignorować pliku robots.txt podczas indeksowania witryny?
- 4. Nie mam pliku robots.txt. Czy wyszukiwarki indeksują moją witrynę?
- 5. Czy mogę użyć Noindex w pliku robots.txt zamiast Disallow?
- 6. Które wyszukiwarki obsługują plik robots.txt?
- 7. Jak uniemożliwić wyszukiwarkom indeksowanie wyników wyszukiwania na mojej stronie WordPress?
Czego możesz się spodziewać po tym artykule
W tym artykule wyjaśniono, czym jest plik robots.txt i jak można go skutecznie wykorzystać do:
- Wyszukiwarki uniemożliwiają dostęp do niektórych części witryny
- Unikaj powielania treści
- Spraw, by wyszukiwarki skuteczniej indeksowały Twoją witrynę.
Co to jest plik robots.txt?
Plik robots.txt przekazuje reguły obsługi Twojej witryny dla wyszukiwarek.
Zanim wyszukiwarka odwiedzi normalne strony w witrynie, najpierw próbuje pobrać plik robots.txt, aby sprawdzić, czy istnieją specjalne instrukcje dotyczące indeksowania witryny. Nazywamy te instrukcje „wytycznymi”.
Jeśli nie ma pliku robots.txt lub nie zdefiniowano odpowiednich wytycznych, wyszukiwarki uznają, że mogą zaindeksować całą witrynę.
Chociaż wszystkie główne wyszukiwarki szanują plik robots.txt, wyszukiwarki mogą nadal ignorować plik robots.txt lub niektóre jego części. Dlatego ważne jest, aby zdać sobie sprawę, że plik robots.txt to tylko zbiór wytycznych, a nie mandat.
Synonimy dla
Plik robots.txt nazywany jest również protokołem wykluczania robotów, standardem wykluczania robotów lub protokołem robots.txt .
Dlaczego plik robots.txt jest tak ważny?
Plik robots.txt jest bardzo ważny z punktu widzenia optymalizacji pod kątem wyszukiwarek (SEO). Informuje wyszukiwarki, w jaki sposób mogą najlepiej indeksować Twoją witrynę.
Dzięki plikowi robots.txt możesz zabronić wyszukiwarkom dostępu do określonych części witryny, zapobiegać problemom z powielaniem treści i wskazywać wyszukiwarkom, w jaki sposób mogą wydajniej indeksować witrynę .
Przykład
Weźmy na przykład następującą sytuację:
Zarządzasz witryną e-commerce, na której użytkownicy z filtrem mogą łatwo wyszukiwać produkty. Jednak ten filtr generuje strony, które pokazują prawie taką samą zawartość jak inne strony. Ten filtr jest bardzo przydatny dla odwiedzających, ale jest mylący dla wyszukiwarek, ponieważ powoduje powielanie treści. Chcesz uniemożliwić wyszukiwarkom indeksowanie tych filtrowanych stron, ale raczej nie marnować czasu na indeksowanie tych adresów URL za pomocą filtrowanej zawartości.
Możesz również zapobiec problemom z powielaniem treści za pomocą kanoniczny adres URL lub tag meta robots, ale oba nie zapewniają, że wyszukiwarki przeszukują tylko najważniejsze strony w Twojej witrynie. Kanoniczny adres URL i tag meta robota nie uniemożliwiają wyszukiwarkom indeksowania stron , ale tylko zapewniają, że wyszukiwarki nie wyświetlają stron w wynikach wyszukiwania . Ponieważ wyszukiwarki mogą spędzać ograniczoną ilość czasu na indeksowaniu witryny, upewnij się, że wyszukiwarki spędzają ten czas na stronach, które chcesz wyświetlać w wynikach wyszukiwania.
Czy twój robots.txt działa przeciwko tobie?
Nieprawidłowa konfiguracja pliku robots.txt może mieć negatywny wpływ na SEO. Sprawdź szybko, jeśli tak jest!
Czy to wygląda na plik?
Zobacz poniżej prosty przykład tego, jak może wyglądać plik robots.txt dla WordPressa:
Agent użytkownika: * Disallow: / wp-admin /
Struktura powyższego pliku robots.txt jest następująca:
Agent użytkownika: agent użytkownika wskazuje, dla których wyszukiwarek wytyczne są przeznaczone.
*: Oznacza to, że wytyczne są przeznaczone dla wszystkich wyszukiwarek.
Disallow: ta wskazówka wskazuje, która treść nie jest dostępna dla agenta użytkownika.
/ wp-admin /: To ścieżka, która nie jest dostępna dla agenta użytkownika.
Podsumowując: ten plik robots.txt mówi wszystkim wyszukiwarkom, że katalog / wp-admin / nie jest dla nich dostępny.
Agent użytkownika w robots.txt
Każda wyszukiwarka powinna identyfikować się z tak zwanym agentem użytkownika. Na przykład roboty Google identyfikują się jako Googlebot, roboty Yahoo jako Slurp, a roboty Binga jako BingBot i tak dalej.
Agent użytkownika ogłasza rozpoczęcie szeregu wytycznych. Wskazówki zawarte między pierwszym agentem użytkownika a następującym agentem użytkownika są używane jako wytyczne przez pierwszego agenta użytkownika.
Wytyczne mogą być ukierunkowane na konkretne aplikacje użytkownika, ale mogą również dotyczyć wszystkich aplikacji użytkownika. W tym drugim przypadku używamy następującego symbolu wieloznacznego: User-agent: *.
Zabroń w robots.txt
Możesz zabronić wyszukiwarkom dostępu do określonych plików, sekcji lub stron na Twojej stronie internetowej za pomocą dyrektywy Disallow. Po dyrektywie Disallow określona jest ścieżka, która nie jest dostępna. Jeśli nie zdefiniowano ścieżki, wytyczne są ignorowane.
Przykład
Agent użytkownika: * Disallow: / wp-admin /
Powyższy przykład uniemożliwia wszystkim wyszukiwarkom dostęp do katalogu / wp-admin /.
Zezwól w pliku robots.txt
Dyrektywa Zezwól działa odwrotnie niż dyrektywa Disallow i jest obsługiwana tylko przez Google i Bing. Korzystając ze wskazówek Zezwalaj i Nie zezwalaj, możesz dać wyszukiwarkom dostęp do określonego pliku lub strony w katalogu, który w przeciwnym razie nie byłby dostępny. Po dyrektywie Allow przychodzi ścieżka, która jest dostępna. Jeśli nie zdefiniowano ścieżki, wytyczne są ignorowane.
Przykład
User-agent: * Allow: /media/terms-and-conditions.pdf Disallow: / media /
Powyższy przykład uniemożliwia wszystkim wyszukiwarkom dostęp do katalogu / media /, z wyjątkiem dostępu do pliku /media/terms-and-conditions.pdf.
Ważne: w przypadku jednoczesnego korzystania z wytycznych Zezwalaj i Nie zezwalaj nie należy umieszczać symboli wieloznacznych w pliku robots.txt, ponieważ może to powodować sprzeczne wytyczne.
Przykład sprzecznych wytycznych
User-agent: * Allow: / directory Disallow: /*.html
W takim przypadku wyszukiwarki nie wiedzą, co zrobić z adresem URL http://www.domein.nl/directory.html. Nie jest jasne, czy wyszukiwarki mają dostęp do tego adresu URL.
Umieść każdą wytyczną samodzielnie, ponieważ w przeciwnym razie wyszukiwarki mogą się mylić podczas analizowania pliku robots.txt.
Więc unikaj pliku robots.txt jak poniżej:
User-agent: * Disallow: / directory-1 / Disallow: / directory-2 / Disallow: / directory-3 /
Korzystanie ze znaku wieloznacznego *
Oprócz definiowania agenta użytkownika symbol wieloznaczny służy również do definiowania adresów URL zawierających określony ciąg. Symbol wieloznaczny jest obsługiwany przez Google, Bing, Yahoo i Ask ..
Przykład
Agent użytkownika: * Disallow: / *?
Powyższy przykład uniemożliwia wszystkim wyszukiwarkom dostęp do adresów URL zawierających znak zapytania (?).
Podaj koniec adresu URL za pomocą $
Użyj znaku dolara ($) na końcu ścieżki, aby wskazać koniec adresu URL.
Przykład
Agent użytkownika: * Disallow: /*.php$
Powyższy przykład zabrania wszystkim wyszukiwarkom dostępu do adresów URL kończących się na .php.
Mapa witryny w robots.txt
Mimo że plik robots.txt jest przeznaczony przede wszystkim do wskazywania wyszukiwarkom, które strony nie mogą indeksować , może być również używany do kierowania wyszukiwarek do mapy witryny XML. Jest to obsługiwane przez Google, Bing, Yahoo i Ask.
Mapa witryny XML musi być zawarta w pliku robots.txt jako bezwzględny adres URL. Adres URL nie musi być uruchamiany na tym samym hoście, co plik robots.txt. Zgodnie z najlepszymi praktykami zawsze zalecamy odwoływanie się do mapy witryny XML z pliku robots.txt, nawet jeśli mapa witryny XML została już przesłana ręcznie w Konsoli wyszukiwania Google lub w Narzędziach dla webmasterów Bing. Pamiętaj, że jest więcej wyszukiwarek.
Należy zauważyć, że możliwe jest odwołanie się do wielu map witryn XML w pliku robots.txt.
Przykłady
Wiele map witryn XML:
User-agent: * Disallow: / wp-admin / Sitemap: https://www.example.com/sitemap1.xml Mapa witryny: https://www.example.com/sitemap2.xml
Powyższy przykład uniemożliwia wszystkim wyszukiwarkom dostęp do katalogu / wp-admin / i odnosi się do dwóch map witryn XML: https://www.example.com/sitemap1.xml
i https://www.example.com/sitemap2.xml.
Pojedyncza mapa witryny XML:
User-agent: * Disallow: / wp-admin / Sitemap: https://www.example.com/sitemap_index.xml
Powyższy przykład uniemożliwia wszystkim wyszukiwarkom dostęp do katalogu / wp-admin / i odwołuje się do mapy witryny XML z bezwzględnym adresem URL https://www.example.com/sitemap_index.xml.
Uwagi
Komentarze są umieszczane po „#” i można je umieścić na początku nowego wiersza, a także po prowadnicy na tej samej linii. Komentarze są przeznaczone wyłącznie do użytku przez ludzi.
Przykład 1
# Nie zezwala na dostęp do katalogu / wp-admin / dla wszystkich robotów User-agent: * Disallow: / wp-admin /
Przykład 2
User-agent: * # Dotyczy wszystkich robotów Disallow: / wp-admin / # Nie zezwala na dostęp do katalogu / wp-admin /.
Powyższe przykłady komunikują się tak samo.
Opóźnienie indeksowania w robots.txt
Dyrektywa Crawl-delay jest nieoficjalną dyrektywą, która zapobiega przeciążaniu serwerów żądaniami. Jeśli wyszukiwarki są w stanie przeciążać serwer, dodanie dyrektywy opóźnienia indeksowania jest tylko rozwiązaniem tymczasowym. Prawdziwym problemem jest słaba platforma hostingowa, na której działa Twoja witryna. Radzimy rozwiązać ten problem tak szybko, jak to możliwe.
Wyszukiwarki różnią się od dyrektywy dotyczącej opóźnienia indeksowania. Poniżej wyjaśniamy, jak radzą sobie z tym największe wyszukiwarki.
Google nie obsługuje dyrektywy opóźnienia indeksowania. Google ma jednak funkcję w Konsoli wyszukiwania Google do ustawiania szybkości indeksowania. Wykonaj poniższe czynności, aby ustawić szybkość indeksowania:
- Zaloguj się do Google Search Console.
- Wybierz witrynę, dla której chcesz ustawić szybkość indeksowania.
- Kliknij ikonę koła zębatego w prawym górnym rogu i wybierz „Ustawienia witryny”.
- Na tym ekranie można ustawić prędkość indeksowania za pomocą suwaka. Szybkość indeksowania jest domyślnie ustawiona na „Pozwól Google zoptymalizować moją witrynę (zalecane)”.
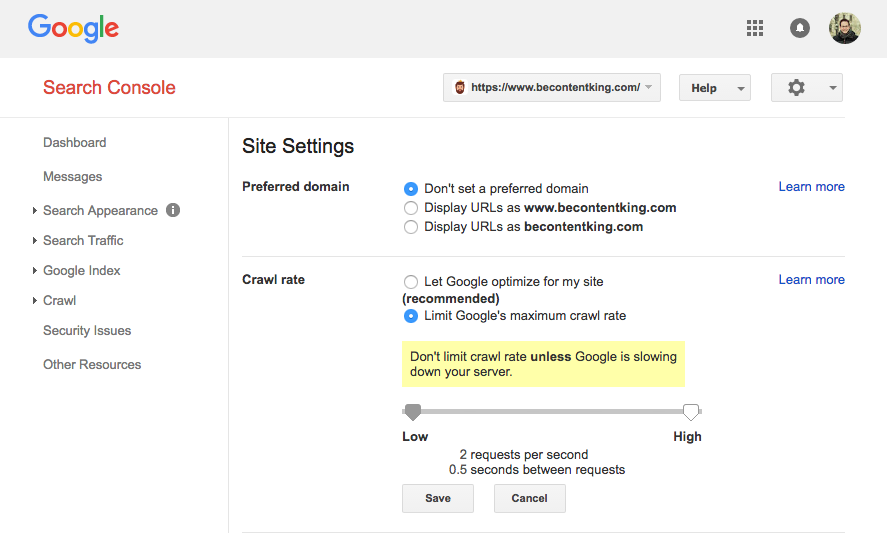
Bing, Yahoo i Yandex
Bing, Yahoo i Yandex wspierają wytyczne dotyczące opóźnienia indeksowania przy ustalaniu maksymalnej prędkości indeksowania (patrz dokumentacja Bing, Yahoo i Yandex). Umieść wytyczną Opóźnienie przeszukiwania natychmiast po zakazie lub Zezwalaj na wskazówki.
Przykład:
User-agent: BingBot Disallow: / private / Crawl-delay: 10
Baidu
Baidu nie obsługuje dyrektywy opóźnienia indeksowania. Możliwe jest jednak ustawienie szybkości indeksowania na koncie Narzędzi dla webmasterów Baidu. Działa to tak samo, jak w Google Search Console.
Kiedy potrzebuję pliku robots.txt?
Radzimy zawsze używać pliku robots.txt. Dodanie pliku robots.txt do witryny nie ma żadnych wad i jest skutecznym sposobem przekazywania instrukcji do wyszukiwarek, w jaki sposób najlepiej zaindeksować witrynę.
Najlepsze praktyki dotyczące pliku robots.txt
Zawsze umieszczaj plik robots.txt w katalogu głównym swojej witryny (najwyższy katalog hosta) i nadaj mu nazwę robots.txt, na przykład: https://www.example.com/robots.txt. W adresie URL pliku robots.txt rozróżniana jest wielkość liter, podobnie jak w przypadku każdego innego adresu URL.
Jeśli wyszukiwarki nie mogą znaleźć pliku robots.txt w domyślnej lokalizacji, zakładają, że nie ma wytycznych dotyczących indeksowania witryny i indeksują wszystko.
Kolejność wytycznych
Ważne jest, aby wiedzieć, że wszystkie wyszukiwarki używają pliku robots.txt inaczej. Pierwsze wspólne wytyczne wygrywają domyślnie.
Jednak Google i Bing patrzą na specyfikę . Na przykład: Zezwól na richtlin wygrywa z dyrektywy Disallow, jeśli liczba znaków jest dłuższa.
Przykład
User-agent: * Zezwól: / about / company / Disallow: / about /
Powyższy przykład uniemożliwia wszystkim wyszukiwarkom, w tym Google i Bing, dostęp do katalogu / about /, z wyjątkiem podkatalogu / about / company /.
Przykład
Agent użytkownika: * Disallow: / about / Allow: / about / company /
Powyższy przykład zabrania wszystkim wyszukiwarkom z wyjątkiem Google i Bing dostępu do katalogu / about /, w tym / about / company /.
Google i Bing mają dostęp, ponieważ dyrektywa Allow jest dłuższa niż dyrektywa Disallow.
Tylko jedna grupa z wytycznymi na robota
Możesz zdefiniować tylko jedną grupę wytycznych dla wyszukiwarki. Uwzględnienie wielu grup wytycznych w pliku robots.txt pomieszało wyszukiwarki.
Bądź jak najbardziej konkretny
Dyrektywa Disallow działa również w przypadku umów częściowych. Podczas definiowania dyrektywy Disallow, aby zapobiec niechcianym wyszukiwarkom z dostępem do plików, bądź jak najbardziej szczegółowy.
Przykład
Agent użytkownika: * Disallow: / katalog
Powyższy przykład zabrania wyszukiwarkom dostępu do:
/ directory /
/ nazwa-katalogu-1
/directory-name.html
/directory-name.php
/ nazwa-katalogu.pdf
Jednocześnie zdefiniuj wytyczne, które są przeznaczone dla wszystkich robotów i wskazówek przeznaczonych dla konkretnego robota
Jeśli wytyczne dla wszystkich robotów są zgodne z wytycznymi dla jednego konkretnego robota, pierwsze wspomniane wytyczne są ignorowane przez specjalnie nazwanego robota. Jedynym sposobem na podążanie za wskazówkami konkretnego robota dla wszystkich robotów jest ponowne zdefiniowanie ich dla konkretnego robota.
Spójrzmy na przykład, który to wyjaśnia:
Przykład
User-agent: * Disallow: / secret / Disallow: / not-launch-yet / User-agent: googlebot Disallow: / not-launch-yet /
Powyższy przykład zabrania wszystkim wyszukiwarkom z wyjątkiem Google dostępu do / secret / i / not-started-yet /. Ten plik robots.txt zabrania tylko Google dostępu do / nie-uruchomiony-jeszcze /, ale po prostu ma dostęp do / tajny /.
Jeśli nie chcesz, aby googlebot miał dostęp do / tajnych / i / nie uruchomionych jeszcze /, powtórz wytyczne googlebot:
User-agent: * Disallow: / secret / Disallow: / not-launch-yet / User-agent: googlebot Disallow: / secret / Disallow: / not-launch-yet /
Plik Robots.txt dla każdej (pod) domeny.
Wskazówki zawarte w pliku robots.txt dotyczą tylko hosta, na którym znajduje się plik.
Przykłady
http://example.com/robots.txt odnosi się do http://example.com, ale nie do http://www.example.com lub https://example.com.
Sprzeczne wytyczne: robots.txt vs. Google Search Console
Jeśli wytyczne w pliku robots.txt kolidują z ustawieniami zdefiniowanymi w Google Search Console, w wielu przypadkach Google wybierze ustawienia zdefiniowane w Google Search Console zamiast wytycznych w robots.txt plik.
Sprawdź robots.txt po uruchomieniu
Po uruchomieniu nowych funkcji lub nowej strony internetowej ze środowiska testowego do środowiska produkcyjnego zawsze sprawdź plik robots.txt w poszukiwaniu Disallow /.
Nie używaj notindeksu w pliku robots.txt
Chociaż niektórzy zalecają stosowanie dyrektywy noindex w pliku robots.txt, nie jest to oficjalny standard. Ponadto Google publicznie wskazane nie używać. Nie jest jasne, dlaczego, ale zalecamy poważne traktowanie ich zaleceń.
Przykłady plików robots.txt
W tym rozdziale podajemy kilka przykładów plików robots.txt.
Wszystkie roboty mają dostęp do całej strony internetowej
Istnieje kilka sposobów informowania wyszukiwarek, że mają dostęp do całej witryny:
Agent użytkownika: * Disallow:
Or
Posiadanie pustego pliku robots.txt lub brak pliku robots.txt.
Brak dostępu dla wszystkich robotów
Agent użytkownika: * Disallow: /
Pro wskazówka: dodatkowy znak może mieć znaczenie.
Brak dostępu do wszystkich botów Google
Agent użytkownika: googlebot Disallow: /
Pamiętaj, że jeśli nie zezwalasz na Googlebota, dotyczy to wszystkich botów Google. Więc także roboty Google, które szukają wiadomości (googlebot-news) lub obrazów (googlebot-images).
Brak dostępu do wszystkich botów Google z wyjątkiem wiadomości Googlebot
User-agent: googlebot Disallow: / User-agent: googlebot-news Disallow:
Brak dostępu do Googlebota i Slurpa
Agent użytkownika: Slurp User agent: googlebot Disallow: /
Brak dostępu do dwóch katalogów dla wszystkich robotów
User-agent: * Disallow: / admin / Disallow: / private /
Brak dostępu do jednego konkretnego pliku dla wszystkich robotów
User-agent: * Disallow: /directory/some-pdf.pdf
Brak dostępu do / admin / dla Googlebota i / private / dla Slurp
Agent użytkownika: googlebot Disallow: / admin / Agent użytkownika: Slurp Disallow: / private /
Robots.txt dla WordPress
Poniższy plik robots.txt został specjalnie zoptymalizowany dla WordPressa, zakładając, że:
- Nie chcesz indeksować sekcji administracyjnej.
- Nie chcę, aby Twoje wewnętrzne strony wyników wyszukiwania w Twojej witrynie były indeksowane.
- Nie chcesz, aby strony archiwum tagów i autora były indeksowane.
- Nie chcesz, aby strona 404 była indeksowana.
User-agent: * Disallow: / wp-admin / #no dostęp do sekcji admin. Disallow: /wp-login.php#no dostęp do sekcji administracyjnej. Disallow: / search / #no dostęp do wewnętrznych stron wyników wyszukiwania. Disallow: *? S = * # brak dostępu do wewnętrznych stron wyników wyszukiwania. Disallow: *? P = * #no dostęp do stron, jeśli permalinki nie działają. Disallow: * & p = * # brak dostępu do stron, jeśli permalinki nie działają. Disallow: * & preview = * #no dostęp do stron podglądu. Disallow: / tag / #no dostęp do tagu stron archiwum Disallow: / author / #no dostęp do stron archiwum autora. Disallow: / 404 error / #no dostęp do strony 404. Mapa witryny: https://www.example.com/sitemap_index.xml
Uwaga: ten plik robots.txt działa w większości przypadków. Upewnij się jednak, że zawsze dostosowujesz je i dostosowujesz do konkretnej sytuacji .
Jakie są ograniczenia robots.txt?
Plik Robots.txt zawiera wytyczne
Chociaż plik robots.txt jest dobrze respektowany przez wyszukiwarki, pozostaje on wytyczną, a nie mandatem.
Strony są nadal wyświetlane w wynikach wyszukiwania
Strony niedostępne dla wyszukiwarek w pliku robots.txt mogą nadal pojawiać się w wynikach wyszukiwania, jeśli są połączone z przeszukiwanej strony. To wygląda tak:

Protip: Możliwe jest usunięcie tych adresów URL z wyników wyszukiwania za pomocą narzędzia do usuwania adresów URL Google Search Console. Pamiętaj, że Google tymczasowo usuwa te adresy URL. Usuń adresy URL ręcznie co 90 dni, aby zapobiec ponownemu pojawieniu się ich w wynikach wyszukiwania.
Buforowanie
Google wskazało, że plik robots.txt jest zazwyczaj buforowany przez 24 godziny. Pamiętaj o tym podczas wprowadzania zmian w pliku robots.txt.
Nie jest jasne, w jaki sposób inne wyszukiwarki obsługują buforowanie plików robots.txt.
Rozmiar pliku
Google obsługuje obecnie maksymalny rozmiar pliku 500 kb dla plików robots.txt. Całą zawartość po tym maksimum można zignorować.
Nie jest jasne, czy inne wyszukiwarki używają maksymalnego rozmiaru pliku.
Często zadawane pytania dotyczące Openta
- Czy mogę użyć pliku robots.txt, aby zapobiec wyświetlaniu stron na stronach wyników wyszukiwania?
- Czy muszę uważać na plik robots.txt?
- Czy ignorowanie pliku robots.txt podczas indeksowania witryny jest nielegalne?
- Nie mam pliku robots.txt. Czy wyszukiwarki indeksują moją witrynę?
- Czy mogę użyć Noindex w pliku robots.txt zamiast Disallow?
- Które wyszukiwarki obsługują plik robots.txt?
- Jak uniemożliwić wyszukiwarkom indeksowanie wyników wyszukiwania w mojej witrynie WordPress?
1. Czy mogę użyć pliku robots.txt, aby zapobiec wyświetlaniu stron na stronach wyników wyszukiwania?
Nie, to będzie wyglądało tak:
Ponadto: jeśli Google nie ma dostępu do strony za pośrednictwem robots.txt, a sama strona zawiera tag <meta name = "robots" content = "noindex, nofollow">, wyszukiwarki nadal będą indeksować stronę. Nie wiedzą o <meta name = "robotach" content = "noindex, nofollow">, ponieważ nie mają dostępu do strony.
2. Czy muszę uważać na plik robots.txt?
Tak, ale nie bój się go używać. To świetne narzędzie do lepszego indeksowania Twojej witryny przez Google.
3. Czy nie wolno ignorować pliku robots.txt podczas indeksowania witryny?
Nie w teorii. Plik robots.txt jest opcjonalną wytyczną dla wyszukiwarek. Z prawnego punktu widzenia nie możemy jednak nic o tym powiedzieć. W razie wątpliwości zasięgnij porady prawnika.
4. Nie mam pliku robots.txt. Czy wyszukiwarki indeksują moją witrynę?
Tak. Jeśli wyszukiwarki nie znajdą pliku robots.txt, zakładają, że nie ma żadnych wytycznych i indeksują całą witrynę.
5. Czy mogę użyć Noindex w pliku robots.txt zamiast Disallow?
Nie, nie zalecamy tego. Google odradza to .
6. Które wyszukiwarki obsługują plik robots.txt?
Wszystkie główne wyszukiwarki obsługują plik robots.txt:
7. Jak uniemożliwić wyszukiwarkom indeksowanie wyników wyszukiwania na mojej stronie WordPress?
Dołącz następujące wskazówki do pliku robots.txt. Zapobiega to indeksowaniu tych stron przez wyszukiwarki, przy założeniu, że nie wprowadzono żadnych zmian w funkcjonowaniu stron wyników wyszukiwania.
Agent użytkownika: * Disallow: /? S = Disallow: / search /
Przeczytaj więcej o robots.txt:
Txt jest tak ważny?Txt działa przeciwko tobie?
Czy to wygląda na plik?
Txt?
Txt?
Txt, aby zapobiec wyświetlaniu stron na stronach wyników wyszukiwania?
Txt?
Txt podczas indeksowania witryny?
Czy wyszukiwarki indeksują moją witrynę?
Txt zamiast Disallow?