Як ми переписали архітектуру Яндекс.Погода і зробили глобальний прогноз на картах
Привіт, Хабр!
Як то кажуть, за традицією раз на рік ми в Яндекс.Погода викочуємо що-небудь новеньке. Спочатку це був Метеум - традиційний прогноз погоди за допомогою машинного навчання, потім наукастінг - короткостроковий прогноз опадів на основі метеорологічних радарів і нейронних мереж. У цьому пості я розповім вам про те, як ми зробили глобальний прогноз погоди і побудували на його основі красиві погодні карти.
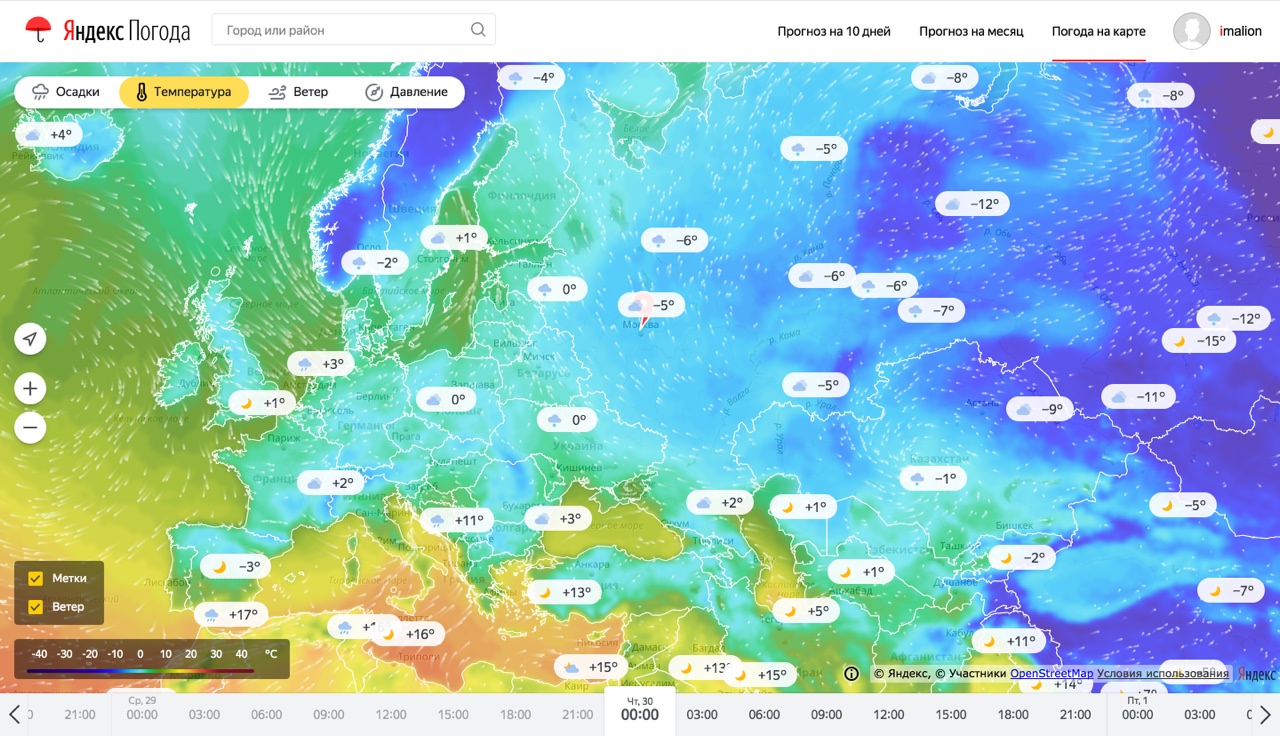
Спершу пару слів про продукт. Погодні карти - спосіб дізнаватися погоду, дуже популярний на заході і поки що не надто популярний в Росії. Причиною тому є, власне, сама погода. Через особливості клімату найбільш населені регіони нашої країни не схильні до раптових погодних катаклізмів (і це добре). Тому інтерес до погоди у жителів цих регіонів швидше побутової. Так, людям в центральній Росії важливо знати, наприклад, яка погода буде в Москві у вихідні або що в четвер у Пітері буде дощ. Таку інформацію найпростіше дізнатися з таблиці, в якій буде дата, час і набір погодних параметрів.
З іншого боку, жителям Східного Побережжя США важливіше знати траєкторію чергового урагану з красивим жіночим ім'ям, а фермерам з Дакоти - стежити за поширенням граду по полях, на яких росте кукурудза. Таку інформацію набагато простіше дізнаватися з карти, ніж з безлічі таблиць. Так і вийшло, що погодні сервіси в Росії - це скоріше таблиці, а на Заході - скоріше карти. Однак, і в Росії існують патерни споживання погоди, коли користувачеві потрібно знати де саме буде погода, яка йому потрібна: це люди, які вибирають місце для пікніка в вихідні, спортсмени, особливо з приставкою "вінд" і "кайт" і, нарешті, дачники . Саме для цих категорій користувачів ми і зробили свій продукт. А тепер я розповім про те, що у нього під капотом.
Ми відразу вирішили, що для побудови карт наш прогноз повинен стати глобальним. Ну хоча б тому, що карти, що покривають не весь земну кулю, віддають середньовіччям. Таким чином, нам потрібно було розширити Метеум до глобального покриття. Однак, попередня архітектура системи погано піддавалася горизонтальному масштабування.
Короткий зміст попередніх серій. Як пам'ятає уважний читач, в першій реалізації Метеума ми розраховували прогноз погоди в міру необхідності. Як тільки користувач потрапляв до нас на сайт, ми збирали для його координат список факторів і передавали в навчену модель Матрикснет. За збір чинників відповідав мікросервіс, який ми називали vector-api. Мікросервіс був хороший всім, крім одного: при додаванні нових факторів і / або при розширенні географії покриття, ми наближалися до межі пам'яті фізичних машин, на яких мікросервіс працював. Крім того, саме по собі формування відповіді підсумкового погодного API містило дорогу по часу і по навантаженню на процесор операцію із застосуванням моделі Матрикснет. Обидва ці чинники сильно перешкоджали побудови глобального прогнозу. Плюс до того, в нашому беклоге утворилася ціла черга з факторів, які збільшували точність прогнозу в експериментах, але не могли поїхати в продакшен в зв'язку з обмеженнями, описаними вище.
Також ми зіткнулися з недоліками обраної архітектури для карти опадів, гаряче полюбилася багатьом користувачам. Для зберігання і обробки даних, необхідних для побудови інформації про опади, використовувалася СУБД PostgreSQL з розширенням PostGIS. Під час літніх гроз кількість запитів в важкі ручки в секунду блискавично перетворювалося з сотень в десятки тисяч, що тягло за собою високе споживання процесорів і мережевих каналів серверів баз даних. Ці обставини послужили додатковим стимулом задуматися про майбутнє сервісу і застосувати інший підхід в обробці і зберіганні погодних даних.
Альтернативою розрахунку погоди в Рантайм був попередній розрахунок прогнозів для великого набору координат по мірі відновлення чинників. Ми зупинилися на глобальній сітці, що покриває сушу з дозволом 2x2 км, а воду - з дозволом 10x10 км. Сітка розбита на квадратики 3 на 3 градуси - ці квадратики дозволяють нам паралельно готувати фактори для моделі і обробляти результати. Ось як це виглядає на карті.
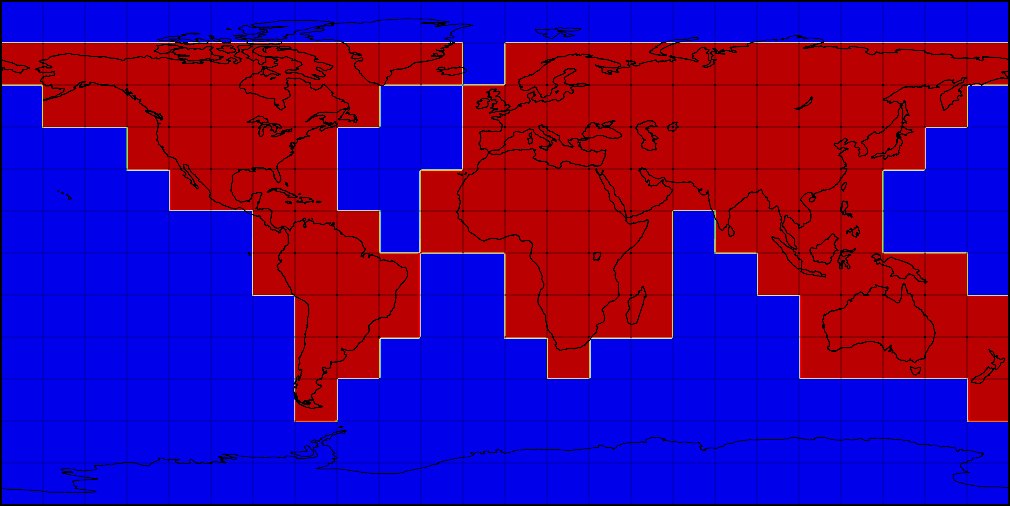
Розбиття областей глобальної регулярної сітки
Процес підготовки погодних факторів починається з кластера Meteo. Відповідно до назви, на цьому кластері відбувається «класична метеорологія». Тут ми завантажуємо дані спостережень і прогнози моделей GFS (США), ECMWF (Англія), JMA (Японія), CMC (Канада), EUMETSAT (Франція), Earth Networks (США) і багатьох інших постачальників. Тут же відбувається розрахунок погодної моделі WRF для найбільш цікавих для нас регіонів. Метеорологічні дані, отримані від партнерів або в результаті розрахунків, зазвичай запаковані в формати GRIB або NetCDF з різними рівнями стиснення. Залежно від постачальника або способу розрахунку, ці дані можуть покривати Московську область або весь світ і важити від 200Мб до 7Гб.
З метеокластера файли з прогнозами погоди потрапляють спочатку в MDS (Media Storage, сховище для великих шматків бінарної інформації), а потім в YT - нашу Яндексовую Map-Reduce систему. Робота в YT ділиться на два етапи, умовно названі "підвіз" і "застосування". Підвіз - це підготовка факторів для подальшого застосування навченої моделі. Фактори треба коректно переінтерполіровать на підсумкову сітку, привести до єдиних одиницях виміру і розрізати на квадратики 3 на 3 градуси для паралельної обробки і застосування. Складність процедури тут полягає в великих обсягах даних і в необхідності проробляти вправу кожен раз, коли прийшли нові дані про прогноз для будь-якої області.
Після того як перший ступінь відпрацювала, починається застосування заздалегідь навчених моделей машинного навчання. У першій реалізації Метеума ми могли прогнозувати тільки два основних погодних параметра за допомогою машинного навчання: це температура і наявність опадів. Тепер, коли ми перейшли на нову схему розрахунків, ми можемо використовувати той же підхід для обчислення інших параметрів погоди. Застосування машинного навчання дає відчутний приріст в точності для нових параметрів: тиску, швидкості вітру і вологості. Помилка прогнозування цих параметрів на 24 години вперед падає на величину до 40%. Крім того, що для багатьох користувачів важливі максимально точні показники вітру і тиску, це улушеніе дозволяє нам більш точно розраховувати ще один популярний параметр - температуру по відчуттях. Він складається зі звичайної температури, швидкості вітру і вологості. Ще одним помітним нововведенням став новий спосіб розрахунку погодних явищ. Тепер в його основі лежить мультіклассіфікаціонная формула - вона визначає не тільки наявність або відсутність опадів, але також їх тип (дощ, сніг, град), а ще наявність і балльность хмарності.
Всі ці моделі потрібно застосувати за обмежений час для кожної точки регулярної сітки. Після того, як моделі застосувались, є ще один шар обробки даних - бізнес-логіка. У цьому розділі ми наводимо змінні, спрогнозовані за допомогою машинного навчання, до потрібних нам одиницям, а також робимо прогноз консистентним. Оскільки прямо зараз моделі ML досить мало знають про фізику процесів, в основному спираючись на чинники, отримані з метеомоделей, ми можемо отримати неконсістентное стан погоди, наприклад "дощ при температурі -10". У нас є ідеї як робити більш правильно в цьому місці, однак прямо зараз це вирішується формальними обмеженнями.
Складність при застосуванні навчених моделей полягає в тому, що для кожного прогнозу треба виконати близько 14 мільярдів операцій. Чинників, необхідних для кожного розрахунку - сотні, і список цих факторів досить рухливий: ми постійно з ними експериментуємо, пробуємо нові, додаємо цілі групи, викидаємо слабкі. Далеко не всі фактори беруться безпосередньо від постачальників. Ми експериментуємо з факторами-функціями декількох параметрів. Правила формування такої кількості фичей дуже складно підтримувати в вигляді коду на Python: громіздко, важко робити ліниві обчислення, важко аналізувати і діагностувати, які фичи (або вихідні дані для фичей) вже не потрібні. Тому ми винайшли свій аналог LISP. Строго кажучи, це не LISP, а вже готове AST, яке дуже схоже на діалект LISP, в якому врахована специфіка наших даних. Процесор цього LISP-а ми зробили таким, як нам треба: ледачим і Кешуються. Тому ми, по-перше, не обчислюємо фактори, які стали вже не потрібні, по-друге, не обчислюємо двічі, то, що потрібно двічі. Ці механізми автоматично поширюються на всі розрахунки. А завдяки тому, що це формальне AST ми можемо: легко аналізувати що потрібно, а що не потрібно; серіалізовать і зберігати окремо частини логіки, писати бізнес-частини в логи, формувати великі частини логіки автоматично (минаючи подання до вигляді коду), версіоніровать їх для проведення експериментів і так далі. Оверхед же вийшов абсолютно незначний, так як всі операції виконуються відразу над матрицями.
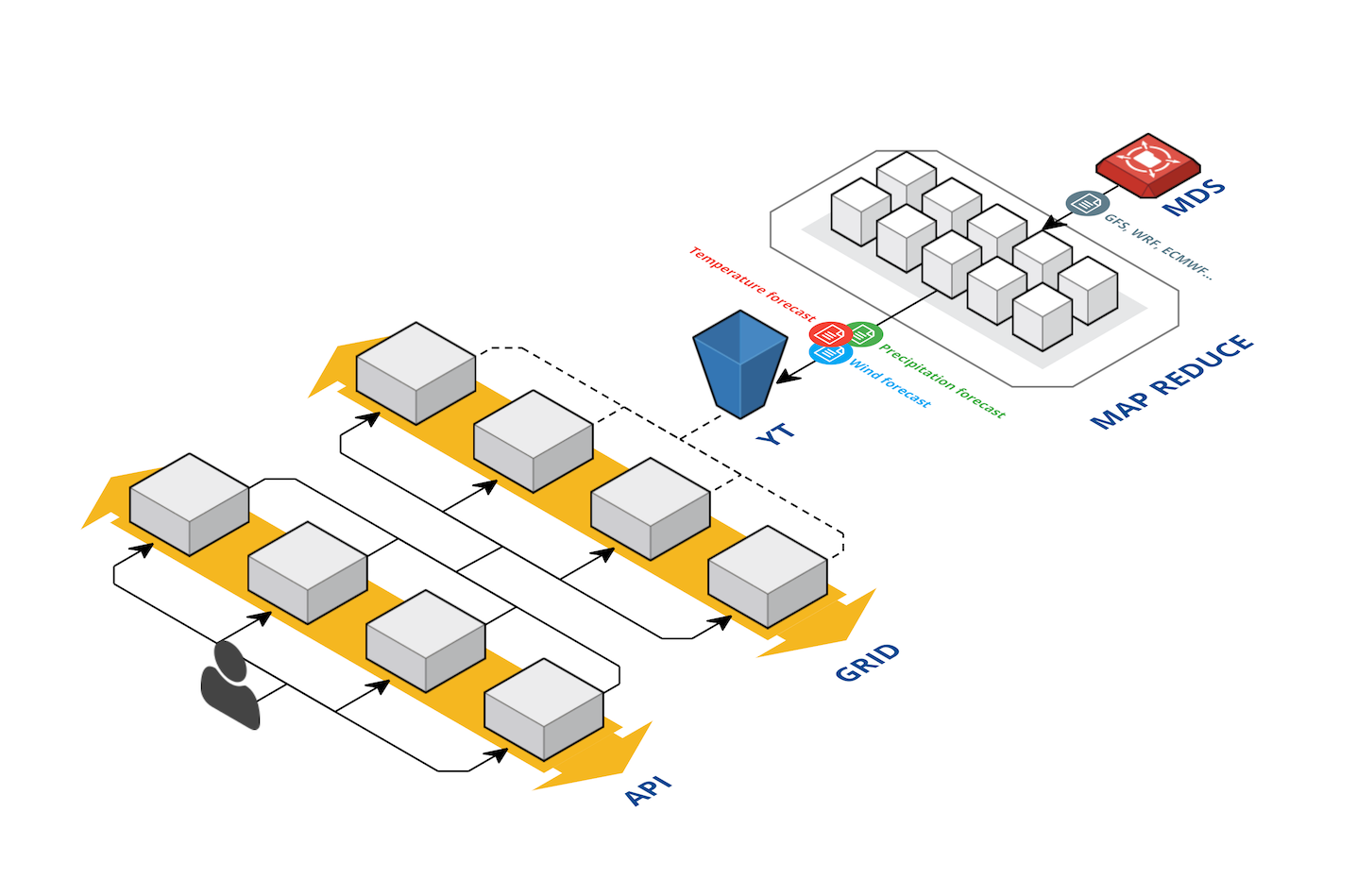
Загальна схема поставки даних в API
Після розрахунку прогнозів ми записуємо їх в спеціальний формат - ForecastContainer і завантажуємо ці контейнери в мікросервіс віддачі даних з пам'яті. Справа в тому, що на весь світ з нашою сіткою в 0.02 градуса виходить близько 1 166 400 000 значень з плаваючою точкою, а це 34Гб даних тільки на один параметр. Таких параметрів у нас більше 50 - тому тримати ці дані повністю в пам'яті однієї фізичної машини не представлялося можливим. Ми почали шукати формат, який підтримує швидке читання стислих даних. Першим кандидатом став HDF5 - у якого є функціональність чанкованія даних і підтримки буфера розпакованих чанкі. Другим кандидатом став наш --самопісний-- пропріетарний формат - матриці float'ов стислі LZ4 і записані в Flatbuffer. Результати тестів показали, що відкриття файлу з даними для роботи займає в два рази менше часуі у Flatbuffers, ніж у HDF5, як і читання довільної точки з кеша. В результаті зараз дані для 50 змінних займають 52.1Гб.
Так як вимоги до споживання пам'яті та часу відповіді були дуже високі ще з постановки завдання, старий мікросервіс написаний на Python ми вирішили переписати на C ++. І це дало свої результати: Час відповіді сервісу в 99 Квантиль впало з 100 мс до 10мс.
Переклад сервісу на нову архітектуру бекенд дозволив нам віддавати прогнози погоди нашим внутрішнім і зовнішнім партнерам безпосередньо, минаючи кеші і розрахунки моделей в Рантайм, дав можливість при термінової необхідності з легкістю масштабувати навантаження з використанням хмарних технологій Яндекса.
Разом, нова архітектура дозволила нам зменшити таймінги відповідей, тримати більші навантаження і позбутися від рассінхрон даних, що віддаються різним партнерам. Дані Яндекс.Погода представлені у великій кількості сервісів Яндекса і не тільки: головна сторінка Яндекса, плагін погоди в яндекс.браузер, погода на Рамблері і так далі. В результаті всі вони отримали можливість віддавати саме ті значення, які в цей момент бачать користувачі основної сторінки Яндекс.Погода .
Для того, щоб отрисовать прогнози на наших нових картах, необхідно досить багато додаткової обробки. Спочатку ми запускаємо MapReduce операції на тих же даних, що віддаються мікросервісом і API для формування даних на весь світ на регулярній широтно-довготною сітці з дозволом в 0.02 градуса. На виході для кожного параметра: температури, тиску, швидкості і напряму вітру, а також для кожного горизонту: часу прогнозу в майбутнє або часу факту в минуле ми отримуємо матриці розміром 9001 * 18000.
Після цього ми будуємо проекцію Меркатора за цими даними і нарізаємо їх на тайли відповідно до вимог API Яндекс.Карт. Тут ми зустрічаємося з однією з найбільших складнощів в ланцюжку підготовки погодних карт: кількістю тайлів, які потрібно оперативно оновлювати при генерації кожного нового прогнозу. Так кожен наступний рівень наближення карти (zoom) вимагає в 4 рази більшої кількості тайлів ніж попередній. Нескладно прикинути, що для всіх рівнів наближення від 0 до 8 потрібно підготувати

картинок. Всього для кожного з чотирьох параметрів ми показуємо 25 горизонтів, з них прогнозів майбутнє 12. Тому кожну годину потрібно оновити 1048560 картинок.
У міру готовності картинок ми завантажуємо їх на карту пам'яті файлів Яндекса з високою паралельною. Як тільки весь шар карти для всіх зумов завантажився, ми підміняємо значення індексу, за яким фронт розуміє, куди йти за новими тайлами. Таким чином досягається досить висока швидкість появи нових прогнозів на карті і консистентность даних в межах часу прогнозу.
Навіть незважаючи на серйозну підготовку на бекенд, отрисовка і анімація погодних карт теж являє собою складну задачу. Розповісти все в одній статті не вийде, тому тут ми зробили акцент на найпомітнішою фиче - отрисовке анімованих частинок, що показують напрямок втерся.
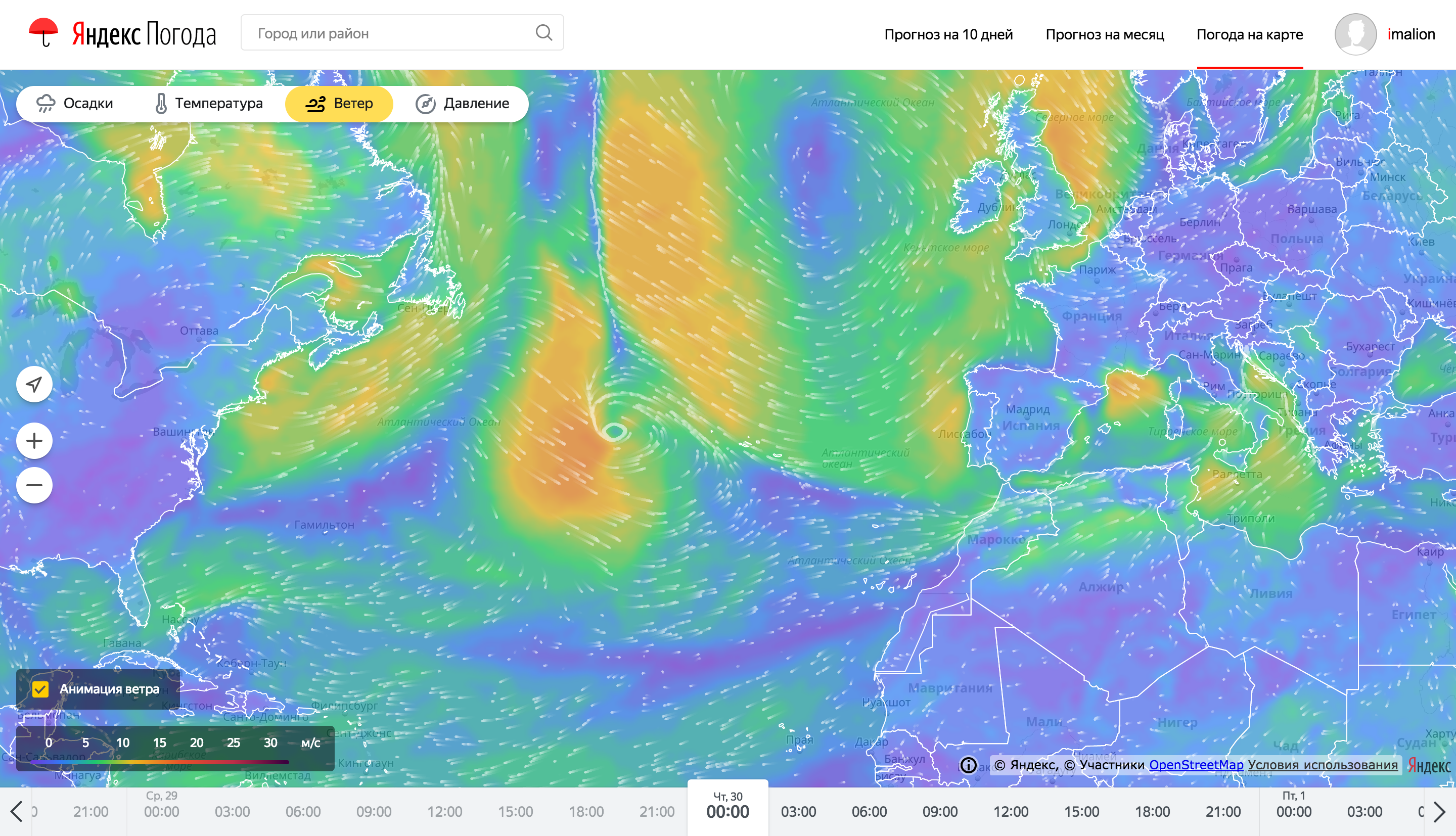
Так виглядають частки анімації вітру на картах погоди
Для оптимізації споживання ресурсів клієнтського пристрою, анімація вітру виконана з використанням WebGL. WebGL дозволяє залучити значні ресурси графічного адаптера, розвантажуючи процесорний потік виконання коду, а також оптимізуючи витрата акумулятора. Завданням процесора в цьому випадку стає установка аргументів виконання шейдерних програм. Для переміщення частинок використовується підхід зберігання положення частинки в 2х колірних каналах текстури для кожної осі (x / y). Таких текстур положення дві: одна зберігає поточний стан частинок, друга призначена для збереження нового стану.
Процес відтворення частинок описаний декількома WebGL програмами. Для більшої сумісності використана перша версія цього стандарту. У браузері використання WebGL виконується через відповідний контекст елемента canvas. Так як графічний прискорювач здатний виконувати в кілька разів більше паралельних операцій через процесор, то переміщення частинок слід виконувати через програму WebGL. Вихідний результат виконання такої програми представляє набір точок в заданому просторі. Це простір за замовчуванням є видимою областю свого canvas, тобто, екраном користувача. Однак є можливість вказати метою відтворення текстуру, використовуючи фреймбуфер.
При старті шару вітру процесор генерує початкове положення частинок, створюючи збірний масив елементів в діапазоні 0 ... 255, в кількості (частки * компоненти) (RGBA). З цього масиву створюються дві WebGL текстури положення. Дані по швидкості вітру також записуються в текстуру, щоб відеокарта мала до них доступ. Червоний і зелений канал цієї текстури містять значення паралельної і меридіональної швидкостей відповідно, причому значення 127 відповідає відсутності вітру, значення менше 127 задають швидкість вітру в негативному напрямку по осі, значення більше - в позитивному. За допомогою підготовлених текстур відбувається отрисовка поточного становища частинок. Після відтворення, одна з текстур положення оновлюється, використовуючи другу текстуру як джерело даних щодо поточного стану. Наступні видимі кадри будуть сформовані за допомогою відтворення попереднього знімка положення частинок зі збільшеною прозорістю, поверх якого буде нанесено поточний стан частинок. Таким чином виходять частинки з затухаючими хвостами.

Так виглядають частки анімації вітру в процесі їх створення
Як виявилося, поточний алгоритм кодування положення частинок в пікселях текстури для якісної візуалізації вимагає підтримки на апаратному рівні високої точності обчислень і float-значень в самих структурах, чого часто немає на мобільних пристроях, тому алгоритм буде перероблений і поліпшений.
Ось приблизно все, що я хотів розповісти вам про архітектуру Яндекс.Погода. За цей рік ми повністю переробили сервіс зсередини (про це йшлося вище) і зовні (практично всі платформи, на яких присутній Я.Погода були істотно перемальовані). Фіналом цих змін стали інтерактивні погодні карти, які ви можете спробувати на нашому сервісі .
Однак, ми ніколи не зупиняємося на досягнутому. У наступному році вас чекає багато цікавих продуктових і технологічних апдейтів: від сервісу, що дозволяє досліджувати клімат в різних куточках Землі до відповіді на питання "чим дихає людина". І це, зрозуміло, далеко не всі. Залишайтеся з нами.
Завжди ваша,
команда Яндекс.Погода