Як Яндекс розпізнає музику з мікрофона
- база треків
- малоперспективні підходи
- Якими ознаками не страшні спотворення?
- Боротьба за точність пошуку
- що почитати
 Пошук по каталогу музики - це завдання, яке можна вирішувати різними шляхами, як з точки зору користувача, так і технологічно. Яндекс вже досить давно навчився шукати і за назвами композицій, та за текстами пісень . На сказані голосом запити про музику ми теж вміємо відповідати в Яндекс.Поіска під iOS і Android, сьогодні ж мова піде про пошук по аудіосигналу, а якщо конкретно - по записаному з мікрофона фрагменту музичного твору. Саме така функція вбудована в мобільний додаток Яндекс.Музика :
Пошук по каталогу музики - це завдання, яке можна вирішувати різними шляхами, як з точки зору користувача, так і технологічно. Яндекс вже досить давно навчився шукати і за назвами композицій, та за текстами пісень . На сказані голосом запити про музику ми теж вміємо відповідати в Яндекс.Поіска під iOS і Android, сьогодні ж мова піде про пошук по аудіосигналу, а якщо конкретно - по записаному з мікрофона фрагменту музичного твору. Саме така функція вбудована в мобільний додаток Яндекс.Музика : 

У світі є лише кілька спеціалізованих компаній, які професійно займаються розпізнаванням музичних треків. Наскільки нам відомо, з пошукових компаній Яндекс став першим, хто став допомагати російському користувачеві у вирішенні цього завдання. Незважаючи на те, що нам належить ще чимало зробити, якість розпізнавання вже можна порівняти з лідерами в цій галузі. До того ж пошук музики за аудіофрагментів не сама тривіальна і освітлена в Рунеті тема; сподіваємося, що багатьом буде цікаво дізнатися подробиці.
Про досягнутому рівні якості
Базовим якістю ми називаємо відсоток валідних запитів, на які дали релевантний відповідь - зараз близько 80%. Релевантний відповідь - це трек, в якому міститься запит користувача. Валідними вважаємо лише ті запити з програми Яндекс.Музика, які дійсно містять музичний запис, а не тільки шум або тишу. При запиті невідомого нам твори вважаємо відповідь свідомо нерелевантних.
Технічно завдання формулюється в такий спосіб: на сервер надходить десятісекундний фрагмент записаного на смартфон аудіосигналу (ми його називаємо запитом), після чого серед відомих нам треків необхідно знайти рівно той один, з якого фрагмент був записаний. Якщо фрагмент не міститься ні в одному відомому треку, так само як і якщо він взагалі не є музичною записом, потрібно відповісти «нічого не знайдено». Відповідати найбільш схожими за звучанням треками в разі відсутності точного збігу не потрібно.
база треків
Як і в веб-пошуку, щоб добре шукати, потрібно мати велику базу документів (в даному випадку треків), і вони повинні бути коректно розмічені: для кожного треку необхідно знати назву, виконавця та альбом. Як ви, напевно, вже здогадалися, у нас була така база. По-перше, це величезне число записів в Яндекс.Музиці, офіційно наданих правовласниками для прослуховування. По-друге, ми зібрали добірку музичних треків, викладених в інтернеті. Так ми отримали 6 млн треків, якими користувачі цікавляться найчастіше.
Навіщо нам треки з інтернету, і що ми з ними робимо Наша мета як пошукової системи - повнота: на кожен валідний запит ми повинні давати релевантний відповідь. У базі Яндекс.Музика немає деяких популярних виконавців, не всі правовласники поки беруть участь в цьому проекті. З іншого боку, то що у нас немає права давати користувачам слухати якісь треки з сервісу, зовсім не означає, що ми не можемо їх розпізнавати і повідомляти ім'я виконавця та назва композиції.
Раз ми - дзеркало інтернету, ми зібрали ID3-теги і дескриптори кожного популярного в Мережі треку, щоб пізнавати і ті твори, яких немає в базі Яндекс.Музика. Зберігати досить тільки ці метадані - по ним ми показуємо музичні відеокліпи, коли знайшлися тільки записи з інтернету.
малоперспективні підходи
Як краще порівнювати фрагмент з треками? Відразу відкинемо явно невідповідні варіанти.
- Побітовое порівняння. Навіть якщо приймати сигнал безпосередньо з оптичного виходу цифрового програвача, неточності виникнуть в результаті перекодування. А протягом передачі сигналу є багато інших джерел спотворень: гучномовець джерела звуку, акустика приміщення, нерівномірна АЧХ мікрофона , Навіть оцифровка з мікрофона. Все це робить непридатним навіть нечітке побітовое порівняння.
- Водяні знаки. Якби Яндекс сам випускав музику або брав участь у виробничому циклі випуску всіх записів, що програються на радіо, в кафе і на дискотеках - можна було б вмонтувати в треки звуковий аналог «Водяних знаків» . Ці мітки непомітні людському вуху, але легко розпізнаються алгоритмами.
- Схожі порівняння спектрограм. Нам потрібен спосіб несуворого порівняння. подивимося на спектрограми оригінального треку і записаного фрагмента. Їх цілком можна розглядати як зображення, і шукати серед зображень всіх треків саму схожу (наприклад, порівнюючи як вектори за допомогою однієї з відомих метрик, таких як L² ):

Але в застосуванні цього способу «в лоб» є дві складності:
а) порівняння з 6 млн картинок - очевидно, дорога операція. Навіть огрубіння повної спектрограми, яке в цілому зберігає властивості сигналу, дає кілька мегабайт незжатих даних.
б) виявляється що одні відмінності більш показові, ніж інші.
У підсумку, для кожного треку нам потрібно мінімальну кількість найбільш характерних (тобто коротко і точно описують трек) ознак.
Якими ознаками не страшні спотворення?
Основні проблеми виникають через шум і спотворень на шляху від джерела сигналу до оцифровки з мікрофона. Можна для різних треків зіставляти оригінал з фрагментом, записаним в різних штучно зашумлений умовах - і по безлічі прикладів визначити, які характеристики найкраще зберігаються. Виявляється, добре працюють піки спектрограми, виділені тим чи іншим способом - наприклад як точки локального максимуму амплітуди. Висота піків не підходить (АЧХ мікрофона їх змінює), а ось їх місце розташування на сітці «частота-час» мало змінюється при зашумлення. Це спостереження, в тому чи іншому вигляді, використовується в багатьох відомих рішеннях - наприклад, в Echoprint . В середньому на один трек виходить близько 300 тис. Піків - такий обсяг даних набагато більш реально зіставляти з мільйонами треків в базі, ніж повну спектрограму запиту.
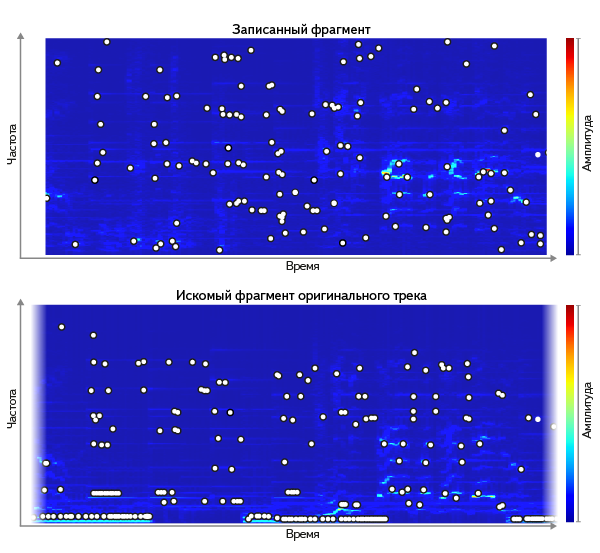
Але навіть якщо брати тільки розташування піків, тотожність безлічі піків між запитом і відрізком оригіналу - поганий критерій. За великим відсотком свідомо відомих нам фрагментів він нічого не знаходить. Причина - в погрішності при записі запиту. Шум додає одні піки, глушить інші; АЧХ всієї середовища передачі сигналу може навіть зміщувати частоту піків. Так ми приходимо до нестрогому порівнянні безлічі піків.
Нам потрібно знайти у всій базі відрізок трека, найбільш схожий на наш запит. Тобто:
- спочатку в кожному треку знайти таке зміщення за часом, де б максимальне число піків співпало із запитом;
- потім з усіх треків вибрати той, де збіг виявився найбільшим.
Для цього будуємо гістограму: для кожної частоти піку, яка присутня і в запиті, і в треку, відкладаємо +1 по осі Y в тому зміщенні, де знайшлося збіг:
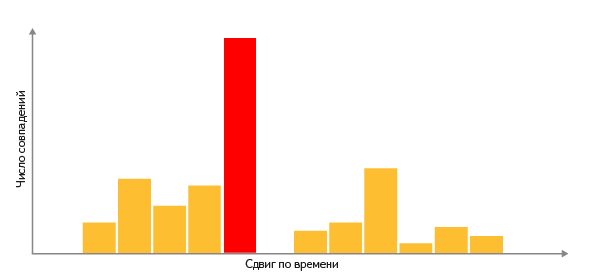
Трек з самої високим стовпчиком в гістограмі і є самий релевантний результат - а висота цього стовпця є мірою близькості між запитом і документом.
Боротьба за точність пошуку
Досвід показує, що якщо шукати по всьому піках рівнозначно, ми будемо часто знаходити невірні треки. Але ту ж міру близькості можна застосовувати не тільки до всієї сукупності піків документа, але і до будь-якого подмножеству - наприклад, тільки до найбільш відтвореним (стійким до спотворень). Заодно це і здешевить побудова кожної гістограми. Ось як ми вибираємо такі піки.
Відбір за часом: спочатку, всередині однієї частоти, по осі часу від початку до кінця запису запускаємо уявне «опускається лезо». При виявленні кожного піку, який вище поточного становища леза, воно зрізає «верхівку» - різницю між становищем леза і висотою свежеобнаруженного піку. Потім лезо піднімається на первісну висоту цього піку. Якщо ж лезо не "виявило» піку, воно трохи опускається під власною вагою.
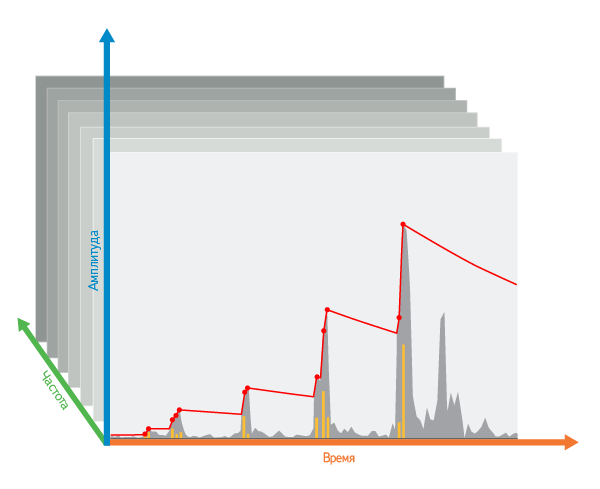
Різноманітність по частотах: щоб віддавати перевагу найбільш різноманітним частотам, ми піднімаємо лезо не тільки в самій частоті чергового піка, а й (в меншій мірі) в сусідніх з нею частотах.
Відбір по частотах: потім, всередині одного тимчасового інтервалу, серед всіх частот, вибираємо самі контрастні піки, тобто найбільші локальні максимуми серед зрізаних «верхівок».
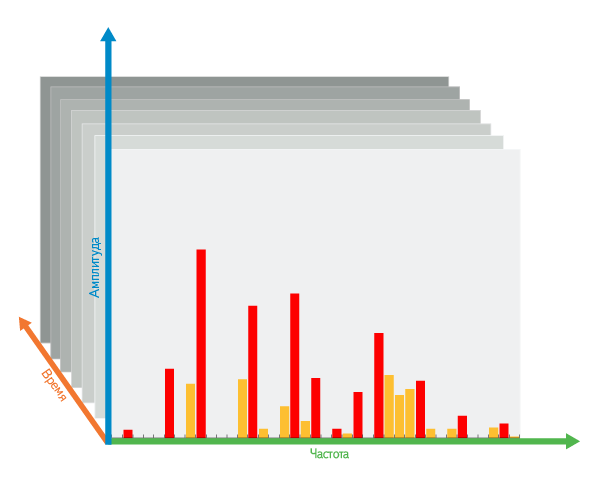
При відборі піків є кілька параметрів: швидкість опускання леза, число обираних піків в кожному часовому інтервалі і околиця впливу піків на сусідів. І ми підібрали таку комбінацію, при якій залишається мінімальне число піків, але майже всі вони стійкі до спотворень.
прискорення пошуку
Отже, ми знайшли метрику близькості, добре стійку до спотворень. Вона забезпечує високу точність пошуку, але потрібно ще й домогтися, щоб наш пошук швидко відповідав користувачеві. Для початку потрібно навчитися вибирати дуже мале число треків-кандидатів для розрахунку метрики, щоб уникнути повного перебору треків при пошуку.
Підвищення унікальності ключів: Можна було б побудувати індекc
Частота піку → (Трек, Розташування в ньому).
На жаль, такої «словник» можливих частот занадто бідний (256 «слів» - інтервалів, на які ми розбиваємо весь частотний діапазон). Більшість запитів містить такий набір «слів», який знаходиться в більшості з наших 6 млн документів. Потрібно знайти більш відмінні (discriminative) ключі - які з великою ймовірністю зустрічаються в релевантних документах, і з малою в нерелевантних.
Для цього добре підходять пари близько розташованих піків. Кожна пара зустрічається набагато рідше.
У цього виграшу є своя ціна - менша ймовірність відтворення в спотвореному сигналі. Якщо для окремих піків вона в середньому P, то для пар - P2 (тобто свідомо менше). Щоб компенсувати це, ми включаємо кожен пік відразу в кілька пар. Це трохи збільшує розмір індексу, але радикально скорочує число марно розглянутих документів - майже на 3 порядки:
Оцінка виграшу Наприклад, якщо включати кожен пік в 8 пар і «упакувати» кожну пару в 20 біт (тоді число унікальних значень пар зростає до ≈1 млн), то:
- число ключів в запиті росте в 8 разів
- число документів на ключ зменшується в ≈4000 раз: ≈1 млн / 256
- разом, число марно розглянутих документів зменшується в ≈500 раз: ≈4000 / 8
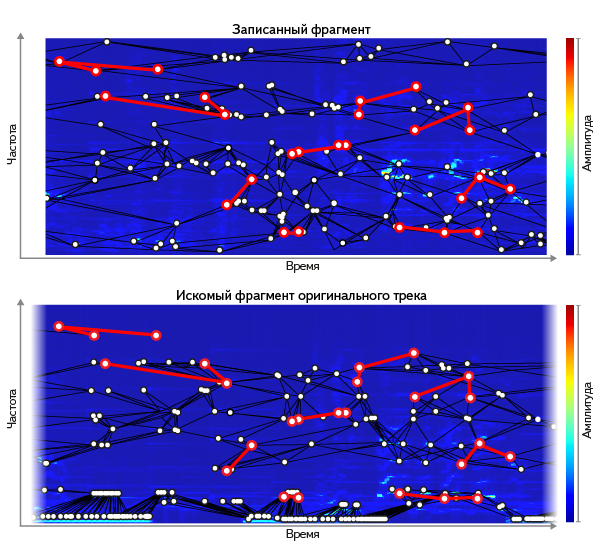
Відібравши за допомогою пар мале число документів, можна переходити до їх ранжирування. Гістограми можна з тим же успіхом застосовувати до парам піків, замінивши збіг однієї частоти на збіг обох частот в парі.
Двоетапний пошук: для додаткового зменшення обсягу розрахунків ми розбили пошук на два етапи:
- Робимо попередній відбір (pruning) треків по дуже розрідженому набору найбільш контрастних піків. Параметри відбору підбираються так, щоб максимально звузити коло документів, але зберегти в їх числі найбільш релевантний результат
- Вибирається гарантовано найкраща відповідь - для відібраних треків вважається точна релевантність по повнішої вибірці піків, вже за індексом з іншою структурою:
Трек → (Пара частот, Розташування в треку).
В результаті всіх описаних оптимізацій вся база, необхідна для пошуку, стала в 15 разів менше, ніж самі файли треків.
Індекс в пам'яті: І нарешті, щоб не чекати звернення до диска на кожен запит, весь індекс розміщений в оперативній пам'яті і розподілений по безлічі серверів, тому що займає одиниці терабайт.
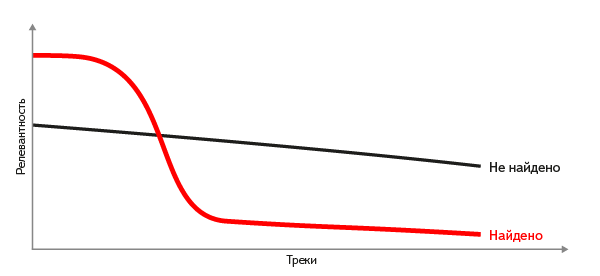
Нічого не знайдено?
Трапляється, що для запитаного фрагмента або немає відповідного треку в нашій базі, або фрагмент взагалі не є записом якого-небудь треку. Як прийняти рішення, коли краще відповісти «нічого не знайдено», ніж показати «найменш невідповідний» трек? Відсікати по якомусь порогу релевантності не вдається - для різних фрагментів поріг різниться багаторазово, і єдиного значення на всі випадки просто не існує. А ось якщо впорядкувати відібрані документи за релевантністю, форма кривої її значень дає хороший критерій. Якщо ми знаємо релевантний відповідь, на кривій чітко видно різке падіння (перепад) релевантності, і навпаки - полога крива підказує, що підходять треків, не знайдено.
Що далі
Як вже говорилося, ми на початку великого шляху. Попереду цілий ряд досліджень і доробок для підвищення якості пошуку: наприклад, в разі спотворення темпу і підвищеного шуму. Ми обов'язково спробуємо застосувати машинне навчання, щоб використовувати більш різноманітний набір ознак і автоматично вибирати з них найбільш ефективні.
Крім того, ми плануємо инкрементальное розпізнавання, тобто давати відповідь вже за першими секундам фрагмента.
Інші завдання аудіопоіска по музиці
Область інформаційного пошуку по музиці далеко не вичерпується завданням з фрагментом з мікрофона . Робота з «чистим», незашумлённим сигналом, зазнало лише перетискання, дозволяє знаходити дублюються треки в великої колекції музики, а також виявляти потенційні порушення авторського права. А пошук неточних збігів і різного виду схожості - цілий напрям, що включає в себе пошук кавер-версій і реміксів, витяг музичних характеристик (ритм, жанр, композитор) для побудови рекомендацій, а також пошук плагіату.
Окремо виділимо завдання пошуку по наспівати уривку. Вона, на відміну від розпізнавання за фрагментом музичної записи, вимагає принципово іншого підходу: замість аудіозаписи, як правило, використовується нотне представлення твору, а часто і запиту. Точність таких рішень виходить сильно гірше (як мінімум, через незрівнянно більшого розкиду варіацій запиту), а тому добре вони пізнають лише найбільш популярні твори.
що почитати
- Avery Wang: «An Industrial-Strength Audio Search Algorithm» , Proc. 2003 ISMIR International Symposium on Music Information Retrieval, Baltimore, MD, Oct. 2003. Ця стаття вперше (наскільки нам відомо) пропонує використовувати піки спектрограми і пари піків як ознаки, стійкі до типових перекручувань сигналу.
- D. Ellis (2009): «Robust Landmark-Based Audio Fingerprinting» . У цій роботі дається конкрентой приклад реалізації відбору піків і їх пар за допомогою «decaying threshold» (в нашому вільному перекладі - «опускається леза»).
- Jaap Haitsma, Ton Kalker (2002): «A Highly Robust Audio Fingerprinting System» . В даній статті запропоновано кодувати послідовні блоки аудіо 32 бітами, кожен біт описує зміна енергії в своєму діапазоні частот. Описаний підхід легко узагальнюється на випадок довільного кодування послідовності блоків аудіосигналу.
- Nick Palmer: «Review of audio fingerprinting algorithms and looking into a multi-faceted approach to fingerprint generation» . Основний інтерес в даній роботі представляє огляд існуючих підходів до вирішення описаної задачі. Також описані етапи можливої реалізації.
- Shumeet Baluja, Michele Covell: «Audio Fingerprinting: Combining Computer Vision & Data Stream Processing» . Стаття, написана колегами з Google, описує підхід на основі вейвлетів з використанням методів комп'ютерного зору.
- Arunan Ramalingam, Sridhar Krishnan: «Gaussian Mixture Modeling Using Short Time Fourier Transform Features For Audio Fingerprinting» (2005). У даній статті пропонується описувати фрагмент аудіо за допомогою моделі гауссова сумішей поверх різних ознак, таких як ентропія Шеннона, ентропія Рен `ї, спектрольние центроїди, мелкепстральние коефіцієнти та інші. Наводяться порівняльні значення якості розпізнавання.
- Dalibor Mitrovic, Matthias Zeppelzauer, Christian Breiteneder: «Features for Content-Based Audio Retrieval» . Оглядова робота про аудіо-ознаки: як їх вибирати, якими властивостями вони повинні володіти і які існують.
- Natalia Miranda, Fabiana Piccoli: «Using GPU to Speed Up the Process of Audio Identification» . У статті пропонується використання GPU для прискорення обчислення сигнатур.
- Shuhei Hamawaki, Shintaro Funasawa, Jiro Katto, Hiromi Ishizaki, Keiichiro Hoashi, Yasuhiro Takishima: «Feature Analysis and Normalization Approach for Robust Content-Based Music Retrieval to Encoded Audio with Different Bit Rates.» MMM 2009: Додати 298-309. У статті акцентується увага на підвищенні робастности уявлення аудіосигналу на основі крейда-кепстральних коефіцієнтів (MFCC). Для цього використовується метод нормалізації кепстра (CMN).
Нічого не знайдено?
Як прийняти рішення, коли краще відповісти «нічого не знайдено», ніж показати «найменш невідповідний» трек?